fsynth retrospective
Introduction
This is a retrospective on the development of fsynth.com (also called Fragment), a
free and open source real-time collaborative cross-platform
audiovisual live environment with a sound synthesis
environment based on pixel data. (oscillator-bank and
filter-bank concept)

logo made with GeoGebra
The project was developed from 2016 to 2021, it didn't gain
much momentum due to too steep learning curve and weird concept but
i had massive fun in the journey (especially the audio server), it
is a big project from which i learned a lot.
The whole project can be seen as a big experiment, both in
term of synthesizer and in term of software architecture.
Many peoples asked me about this project over the years, it is
based on simple concepts but is hard to understand if you are not
into sounds or accustomed to the idea of spectral synthesis, it is
also quite focused on code so arcane if you don't care about that
and especially accelerated graphics code so it is even more arcane
and confusing if you try to relate it to audio... !
I will not talk much about spectral synthesis or how to do
stuff with it as all of that is either on the website, YouTube videos
or documentation
but i will try to talk about what i did with it and the highlights,
technical stuff and ideas / architecture / development
process.
The beginning / idea / tools
My interest in sound synthesis probably started soon after i
started making music in ~2007 (which was mainly triggered by the
demoscene and my growing love of electronics music), i started by
tinkering with Renoise DAW
(also a bit of Reason) and
lots of audio
plugins progressively modifying patches (aka synth.
programming) and making my own sounds, also read plenty stuff about
old and new synthesizers and DSP
algorithms, i also experimented with many sound synthesis
methods or dive into old tech such as tape loop although i
mainly stayed with digital stuff.
I don't think i ever liked composing music though, always was
too cumbersome for me, what i enjoy the most is definitely jamming,
hearing new sounds or reproducing sounds and making up soundscape
with lots of layers and some bits of progression.
The continued interest in sounds led me up to read lots of
related materials and i eventually reached a point where i knew off
many software which worked with sounds in an "uncommon" way such as
MetaSynth,
Virtual ANS,
Photosounder, AudioSculpt,
also knew a lot of related synth / interface oddities as well such
as UPIC, HighC, Reaktor, Kawai
K5000, ANS and sound
design languages such as Kyma,
SuperCollider,
Pure Data,
Chuck.
I then tinkered with custom sounds generator although all my
early experiments were very crude and i didn't know much what i was
doing, the motivation at the time was mostly about real-time sounds
for 1k or 4k demos.
An idea that i started being obsessed with is sound synthesis
using image-based approach, sculpting the sound by directly editing
the spectrogram likes
you would do in a graphics program, i especially liked MetaSynth approach
early on but this software was only available on Macintosh so i
tried alternatives which worked on Windows / Linux such as Virtual ANS which also led
me down the rabbit hole of sound synthesis history, discovering
oddities such as the ~1950s ANS
synthesizer, Daphne Oram
Oramics,
Hugh Le Caine
experiments or Delia
Derbyshire work.


early Virtual ANS experiments with ambient sounds and a
composition
on the right

composition and
ambient drone on
the right, the original files are available by replacing .ogg by
.png in the URL
The concept of this approach is simple :
- the vertical axis represent the oscillator bank, sine wave oscillators are mapped to the Y axis following a logarithmic scale (because our hearing works on a logarithmic scale)
- the horizontal axis represent time
- the pixel brightness is the oscillator amplitude which relate to sound level
The reason i was obsessed with this approach was that it pack
both timbre generation and composition through a graphics score, it
is intuitive and matched my interest of computer graphics and
growing interest of sound synthesis, it is also a fun way to
understand one of the simplest and oldest way to generate sounds :
additive
synthesis
The obsession didn't get away, i wanted to do my own
image-based synthesizer akin to MetaSynth with more features than
just sketching with brushes, the first synthesizer prototype was
made in C for the GP2X in early 2010s, this
is where i experimented with the oscillator-bank concept which is
basically straightforward additive
synthesis, adding huge amount of sine waves together at
different frequencies to produce sounds.
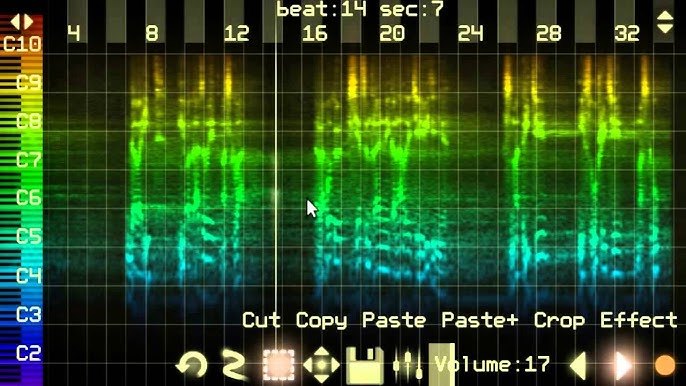
Virtual ANS program, one
of the main inspiration for Fragment
CSP
CSP
(Collaborative Sound Painting) prototype was made in mid 2015, one
year before the prototype of Fragment, CSP was a web version of the
Virtual ANS software with a similar score view, brushes and drawing
tools, it support smooth real-time playback (additive synthesis),
audio chunks are generated on the fly using web workers, the editor
was pretty similar to Virtual ANS editor although it had scriptable
(sand-boxed
JavaScript) post-processing snippets which could be applied to
multiple selections.
{kind=link}
screenshot of the app, see also a video of CSP
This program was pushed quite far in term of features, i never
managed to release it though, it had most features of Virtual ANS,
the code was rushed though and required some refactor at some
point, some features such as the multi selection / sand-boxed
post-processing broke on later browser versions, a huge factor in
its abandon.
The "novel" idea at the time was the flexible post-processing,
i wanted to apply image processing algorithms to parts of the
sonogram and hear the result, i also could add some features of
MetaSynth quickly by doing snippets without having to mess with the
UX / code.
The other "novel" idea was the collaborative aspect which may
have been perhaps way more interesting than the collaborative
aspect on Fragment, the idea was a shared canvas that could be
edited by multiple users with a portal to share scores and post
process snippets.
This program would have been way more user-friendly than
Fragment although less powerful.
CSP was 100% vanilla JavaScript just like Fragment with the
same reasons. (see below)
Custom build system
As CSP (and fsynth) started to go beyond a simple prototype i
reached the issue of growing code base and generating code for
different targets, many bulky build tools were available to address
this issue in an optimal way but i still felt it was too much for
me as a solo developer, i also didn't like that it felt likes work
and i especially didn't want to delve into endless configuration
files so i made my own very simple (< 100 lines of code) build
system with Anubis / Python which solved my two growing issues
:
- modularity; being able to split the code base into different parts (now solved with JavaScript modules)
- generating code for different target (optimized code for production etc.)
- the Anubis build tool also had a build on file change feature
which was quite handy
First issue was solved by implementing a simple C style files
preprocessor which took an entry point file and looked for
#include directives in comments. Second issue was solved by
calling external optimization programs on the single file produced
by the preprocessor. This was simple to maintain (= didn't had to
revisit this at all), required almost zero configuration and
produced good enough result for my use case, all of this was also
used to ease the development of Fragment.
The code base also required to be quite careful on how parts
were structured, it was easy to make a mess with this primitive
build system so i restricted the preprocessor to run only on the
entry file (no include directives in other files) and i forced all
my files around a fixed template with sections such as fields,
functions, init. code; it ended up being an okay decision as a solo
dev.
What was missing perhaps was some sort of environment
variables for different targets which was required for the
deployment on my production server (which require a different setup
than a local version), i solved this the ugly way
instead by running a find and replace tool on all the files, a
hacky solution but had few lines to replace anyway...
WUI
WUI is a
collection of lightweight vanilla (standard ~2010s JavaScript) GUI
widgets to build web apps which i purposely started in ~2015 for my
web experiments, CSP in particular, the idea was a complete set of
independent widgets that i could integrate into my experiments as
needed, i never liked big GUI frameworks because they were too big
/ monolithic for my taste, all major updates were breaking stuff in
previous versions and customization was also quite tiresome, they
also rely on complex environment which were too bulky (or too much
likes work) for my experiments.
There is some innovative features in WUI such as detachable
dialogs, dialogs which can be detached from the main window and
still works, it is implemented in a hacky way by overriding
addEventListener but it provide a way to put all parts of an
app into independent window (or tabs) as needed without much issues
as long as you use WUI widgets (not guaranteed with something
else), i thought this kind of stuff would be cool for "big"
monitoring environments where many parts would be monitored over
multiple monitors. Modern libraries still don't support this as far
as i know !
The other unique feature of WUI is the range slider widget
(which also act as an input field) which support MIDI learn feature
and works in absolute or relative mode, this allow MIDI interfaces
to be easily associated with a slider / input.
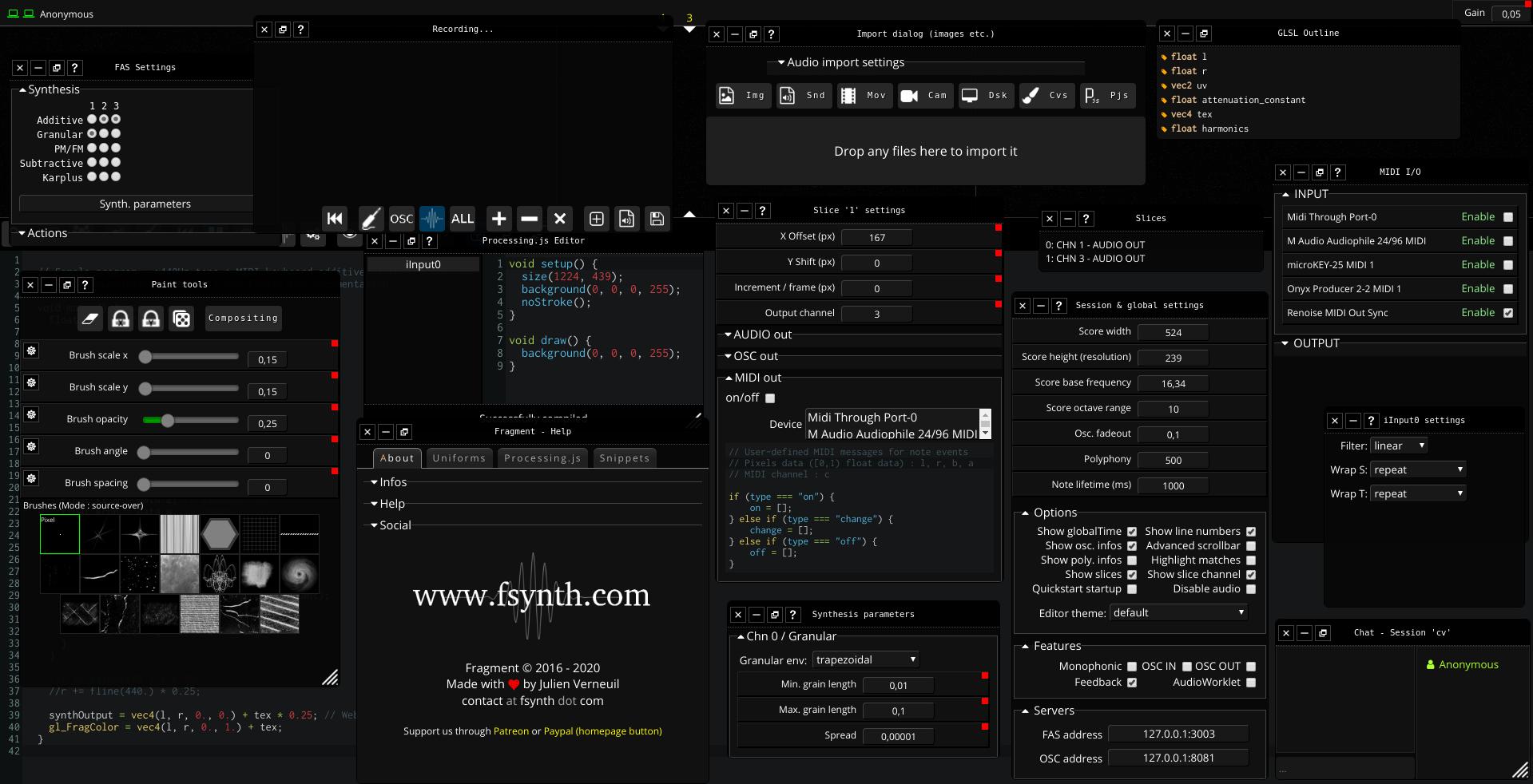
most features of WUI at works on fsynth, most
dialogs can be detached into individual window
There is now much better native solution to build such
framework with Web
components API, i still use my library for quick experiments as
it works flawlessly albeit with an old fashioned API.
Prototype : GLSL image-based synthesizer
The first prototype of
fsynth was a quick weekend project in ~2016 with the idea of
computing the spectrogram in real-time with GPU code.
This prototype is
still working fine and is basically a stripped down lightweight
Fragment (a canvas, a playback marker and a GLSL code editor with
real-time update), the stereo audio is generated by the browser so
it does not require an audio server.
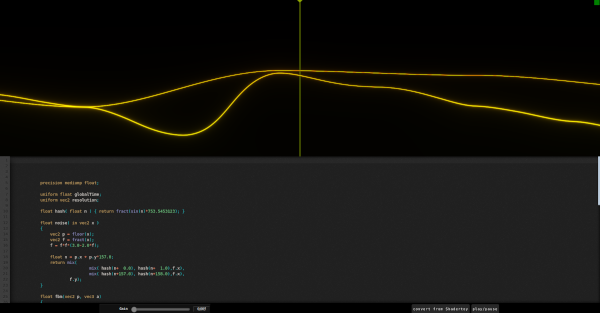
fsynth prototype
The idea was heavily influenced by "Sonographic
Sound Processing" by Tadej Droljc (video) which is a
Max/MSP/Jitter experiment of modifying spectrogram in real-time on
the GPU, the experiment does not use additive synthesis though but
modify the frequencies and then apply an inverse Fourier
transform, this can be faster than doing additive synthesis and
more accurate due to untouched phase, i thought this was impressive
and started to imagine what kind of sounds could be produced by
computing the spectrogram in real-time (= throw accelerated
graphics stuff around) or heavily mangle spectrograms and hear the
result immediately.
I experimented with my prototype for some times and was amazed
at all the noise it was able to produce even though the spectrogram
was all computed (didn't have any bitmap import features) so i
started a second version to add the features it lacked, mainly
multiple playback marker so i could compose sounds through spectrum
slices and shader inputs so i could import bitmap images.
The audio was generated on the main thread
with a WebAudio
ScriptProcessorNode by adding sine waves together computed from
a wave-table, the audio processing done in the main thread was a
well known burden of the Web Audio API at the time so the sound
quality was not that good, this was improved to some extents with
fsynth.
fsynth v1: The launch
The first version of Fragment was released ~4 month after the
prototype, it was an improved version of the prototype with better
UX and some more features but was still using the not so polished
web audio engine, it was still quite rough in some aspect, lacking
documentation and having bugs.
A second update came 3 month after the initial release with
many features plus complete documentation, many update followed
with the final v1 update being released a year after launch, at
this point Fragment had matured with good audio quality and an
improving audio server with support for additive synthesis and
granular
synthesis.
It was well received i believe but the steep learning curve,
weird concept and usability issues fend off many peoples so in the
end i don't think much peoples used it.
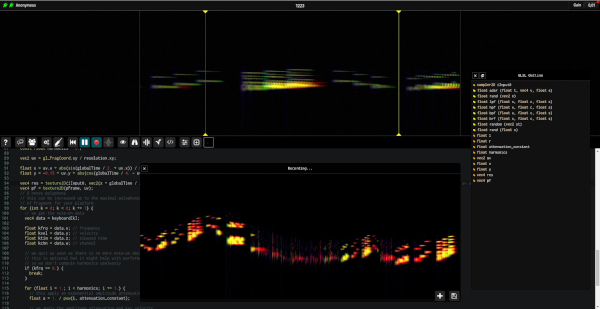
fsynth.com v1 client
Architecture
Fragment is a complex software with several independent parts
and tools all centered around the core of Fragment which is the web
client, the client can be used either locally or online from the
official website, it use a global sessions mechanism handled by
strings, data is shared between users of the same session.
The other parts are :
- a main server which handle the chat and hold session data (slices) it use a Redis database back-end
- a sharedb server which handle session data (settings and code) and the collaborative feature / OT for the code edition component, it use a MongoDB database back-end
- a native high performance audio server which provide on-demand smooth high quality sound synthesis
- NGINX as a reverse proxy (online version), the local version
use an independent web server
The reason for using two type of database back-end was
isolation and scalability, slices were also supposed to be updated
more often than the rest, i think it was a valid choice but it was
not really necessary for the current features state so i am kinda
mixed in the end.
The idea for the architecture was to be highly flexible,
highly scalable and robust, the audio server is the part that
manage all of that ideal.
The scalability is handled by independent programs and most
back-end parts are clustered; most parts of this project is able to
leverage multiple cores or multiple machines even the audio
server.
There is also many tools that were made alongside Fragment
:
- an OSC relay to control external or internal stuff through a simple messages mechanism
- a relay to distribute the client data over multiple instances of the audio server "distributed multi-machines/multi-core realtime sound synthesis"
- an external
GLSL code editor
- a file server which provide a convenient API to manipulate files remotely for the audio server
- a sonogram player web widget
- the audio
server
Most of the project was made in vanilla JavaScript (ECMAScript
version 5), most back-end tools were made with NodeJS.
The vanilla JavaScript choice for the client was mainly due to
mitigate the issue of software rot and
to simplify future development, i think it was an excellent choice
in the end for a solo developer over a 5 years project time frame
because i didn't have to fight with the tooling nor with dead,
deprecated or outdated dependencies, it is also fairly easy for a
newcomer to understand the parts of this project and to hack
it.
For comparison the back-end parts required several refactor
over the years due to deprecated / outdated dependencies.
The vanilla JavaScript drawback is mainly related to the code
which is a bit rushed, many parts of the client probably require
heavy refactoring to cope with side effects and some parts are
probably a mess to understand / a pain to manage. (especially all
the UI related code !)
Graphics
Earliest issue was the performance of the graphics loop which
was intertwined with sound generation, reading the canvas surface
back from the GPU was kinda slow (even if slices were 1px wide) and
could produce stall issues which was partially addressed with
careful optimizations of the graphics loop notably doing minimal
allocations (re-using buffers), can perhaps be more optimized by
using
fences now.
The first version also supported two WebGL version which was
quite a chore to maintain as some features were not available with
WebGL 1 so i had to address them differently such as being limited
to one draw buffer with WebGL 1 which meant no independent output
for sonogram and graphics on the fragment shader, all the
differences induced by this had an impact on the fragment shader
code which was probably very confusing from an user perspective, it
also imposed some limits. It was a mistake to handle both versions
since WebGL 2 had increasing support and WebGL 1 support was
quickly shunned with the v2 in the end.
Audio
The web audio engine was not so good at first due to the audio
processing being done on the same thread as the UX which
interrupted the audio process and ended up in crackling sounds (can
be heard in the early videos), it had too many oscillators which
the Web Audio API wasn't really suited for, it worked ok on Chrome
at some point but was on the edge of being usable on anything else
and still required a lot of computing power.
The audio processing being done in the same thread as
everything else was a well known burden of the Web Audio API at the
time, it can be solved now with AudioWorklet.
A temporary fix to lessen the crackles was to build a standalone
code editor since audio interruptions were worse on code change
due to browser
reflow and shader compilation, this helped quite a lot on some
of my early videos to produce clean sounds.
I did some more fixes to the audio engine to support OscillatorNode
(WebAudio oscillators) instead of a ScriptProcessorNode, this was
better on Chrome since an OscillatorNode was implemented natively
in an optimized manner, it was implementation dependent though and
still worked poorly on Firefox...
I tried many things to improve the performance with
OscillatorNode, first creating oscillators on the fly for each
events, second by having a pool of pre allocated oscillators and
messing with the oscillator gain value on note event.
An idea i didn't try was to pre allocate oscillators
progressively instead of having a big number of already allocated
oscillators, finding a good balance between ready to use
oscillators and real time allocation to alleviate the needs of
maintaining lots of ready but unneeded oscillators which was also a
burden for the browser to maintain.
Other fixes were to minimize browser re-flow and improve the
algorithms but there was limits to that as well.
The complete fix to the crackling audio issue without going
for restrictions was to ditch WebAudio entirely and externalize it
by creating a high performance audio server from the ground up in C
that would be linked to the client with Websockets,
the motivation for this was also the prospect of embedded uses so i
could use the synthesizer on dedicated computers or a network of
computers, something done for example by Kyma (with much better
latency !) or actually all modern digital synthesizers.
Collaborative
Fragment has some collaborative aspect because i ported the
idea of CSP collaborative aspect for fun, the code and most data is
shared across session users, the global clock and media data is not
shared though so there is no real synchronization of audio / visual
happening between users, it is just a mean to quickly get the same
session data which is probably sufficient for simple
jams.
Website
The Fragment website was built with the Skeleton CSS framework and Font Awesome icons as a single page
with bits of JavaScript (using
localStorage) for sessions handling, Skeleton has a clean
modern design and remained very simple under the hood, i added some
customization such as the fixed header and social buttons and added
a Flarum powered forum which was
perhaps the heaviest part of all this because it turned hard to
upgrade later on because it rely on bulky tech...
FAS: Fragment Audio Server
The audio server
was already available at launch albeit in a somewhat unstable form
but it was a good idea as the sound quality quickly improved, it
also paved the road for features that would have been tough to add
with Web Audio alone such as all the goods of externalizing the
synth part which could now be reused for other apps, embedded and
computed across many computers.
The first version of the audio server still had issues with
crackling and many crashes because i was learning audio software
architecture in the process, i iterated on it with many structural
changes for many months until i had a solid architecture which i
believe is pretty similar to "professional" instruments / DAW
although with a different data source.
A very helpful book (along with web articles and papers) for
the audio server was L'audionumérique (don't know
the english title) by Curtis Roads, most
concept covered by this book were implemented in the audio
server.
The first version of the audio server was rough and was only
good for additive synthesis although it had support for FM and
granular synthesis as well. (granular was ok but heavy
computationally)
The audio server is fully documented here with lots of details
about its architecture.

a clustered FAS diy environment with RPI
(running netJACK 2 / FAS) and NanoPI NEO 2 boards (running FAS
instances)
Latency issues
Latency is an important factor in audio, Fragment never did
well on this part even with the audio server, it remains highly
sensitive with heavy latency variations due to GPU / CPU reliance,
the web stack adds to this burden, i also didn't care much about
the client UI code at first so it is probably not helping much,
latency is also due to the lengthy process by which the audio is
generated : GPU -> reading/decoding back GPU content on CPU
-> data transfer to the audio server over websocket ->
decoding note events -> sound generation
There is even more latency issues with multiple audio servers
since it adds a relay program which will distribute the
data.
There is some ways to mitigate this by carefully tuning the
audio server / browser / machine / network but it will never match
a native app unless the client is also native.
v2
Fragment v2 was released in March 2021 and was a labor of love
spanning three years, i was not as focused as before though, this
version brought refinement to almost every parts of the program, it
addressed usability issues with lots of quality of life
improvements as well and i also perfected the audio engine; audio
stability and quality, effects chain and new instruments / custom
ones with Faust was the major focus for the audio server.
Perhaps i could have put some features in the v1 but releases
were already tough to manage as a single developer so i preferred a
quieter approach.
The v2 development was chaotic with long period of doubts
about the direction i should takes with Fragment, mostly thinking
about an embedded product approach and sharing platform which
slowed down the development, in the end i decided that there was
too little interest to push it further or that it required too many
changes with a more intertwined audio / graphics part concept so i
ditched all these ideas and focused on improvements and things i
wanted to experiment with.
Another idea of the v2 was to improve the longevity of
Fragment by adding features such as desktop capture and disabling
audio (to makes Fragment focus on visual experiments) but most
importantly by adding Faust
support on the audio server, with the addition of Faust anybody can
add new algorithms with an elegant language without messing with
the audio server code, this feature could also be used to replace
all custom algorithms of the audio server by robust equivalents so
that it can be used in other products, it can also reduce the
complexity of the audio server code, it makes the audio server
quite generic.
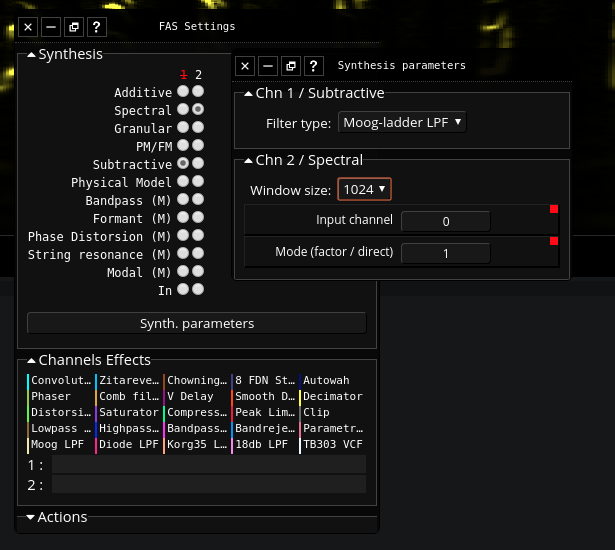
all the new instruments and channel
effects
On the audio server the new features i definitely wanted was
ASIO / Jack
support because i was limited by hardware device channels with
PortAudio,
using Jack allowed "unlimited" output channels and flexible routing
/ instruments, also wanted to improve instruments and add new ones
notably wave-table (additive but with different single cycle
waveform) and band-pass synthesis (to do the inverse of additive;
carving out noise), another huge feature which was missing was
virtual channels (a mixing layer) and sound effects.
On the client part the new features were desktop capture which
would enable Fragment to become easy to experiment with because you
can use any tools you are accustomed with to drive the synthesizer,
MIDI out was also kinda important as i wanted to test triggering
external synths from Fragment events.
For maintenance reasons and because the audio server was
finalized i dropped Web Audio along with WebGL 1.
There is many other new features i
don't discuss here, they were added because i wanted to experiment
with them.
Adding many types of sound synthesis algorithm was fun to do
and experiment with but many types don't blend well with the way
Fragment works so some of them are difficult to use or have limits,
a different approach (UX issue ? parameters encoding ?) may be
required for some of them.
My experiments
Parts of Fragment development was testing / using it (kinds of
poor man QA), this was
a fun part with many random lengthy jam sessions.
Note that plenty early videos are messy with bad audio quality
and most of them without direction except the synthesis type or
some features constraint, i was stressing the synth with lengthy
session to find bugs or things to improve and sometimes trying
ideas that passed by.
Most videos focus on sounds since it is what needed testing
but i also tinkered with the live graphics aspect of Fragment on
some videos.
There is many other videos here : https://www.youtube.com/@FragmentSynthesizer
Bandpass filter-bank
Mix of synthesis type
- Additive / Granular; ambient / rhythmic noise with spectrum feedback (reverb / delay done through real-time sonogram manipulation)
- Additive / FM; with NanoPI NEO2 cluster (demo of embedded audio server with distributed synthesis using Net Jack 2)
- Additive
/ Granular / FM patches + Faust effects
Additive synthesis
- 150 FPS additive synthesis patches; perhaps the best video that shows crude physical modelling (string / plucked string, percussion, wind instruments) with additive synthesis, also harmonics noise
- additive
synthesis with manual control over the harmonics through
OSC
messages
Early :
- Sequences, pads,
transposition of the whole spectrum, spectral
distortions
- Spectral
feedback, distortion, noise and filtering; also synthetic
choir
- Noisy dissonant "metallic" sounds
- Heavy glissando, pipe organ, additive noise
- Additive synthesis demo; emulation of bells, hitting metallic stuff, transient noise that can be found on wind instruments (short attack transient noise)
Wavetable
Phase / Frequency modulation
- Patches;
bells
Themed jams (with visuals)
Did many themed jams with nature videos or demoscene visuals,
i sometimes tried to sync the audio jam to the visuals with limited
success.
- Fragment granular, additive, subtractive, PM chaos; perhaps my best live coding experiment, also contains live coding of visuals and granular synthesis experiments at the end
- Desktop capture visuals
- Additive
/ PM / Granular / Karplus ambient
- FM /
Phase modulation + granular synthesis
- Wavetable /
Additive and Subtractive with heavy play on the filters; quite
like the ending ~20 minutes
- Subtractive / Karplus / PM / Additive / Granular; layered demos visuals with filters, i quite like the ending ~15 minutes
- Karplus-Strong string
synthesis / Additive; layered demos / nature visuals
- Another soundscape with nature visuals
- Granular noisescapes
- v2.0 launch video
Early :
Modal synthesis
- with
wavetable source (mostly failed)
Performance
Few experiments of live interaction where i interact with the
spectrum through visual or other means, i didn't explore this part
much and most the experiments are crude but i think it has
potentials.
- Additive / FM; my best attempt at spectrum manipulation from visuals
- Wavetable; "reading" abstract bitmap graphics
- Wavetable;
part 2;
same as above but desktop capture with visuals from real-time
graphics sketches
- Interaction of videos
with the spectrum (not really successful)
- Same as
above (a bit more successful)
Early :
- Desktop
capture with generative visuals and google images
source
- Interaction of live webcam images on additive synthesis partials
- Painting
sounds (note : mostly failed experiment :P but it show the
crude paint feature)
Browser is not a professional music platform
I had some criticism of the project over the years due to the
web tech stack being "not professional" for audio, i don't think
this was a concern since Fragment is just an experiment, it is true
though that its biggest issue is latency and that the web stack
doesn't help to improve this.
Still, there was many successful web audio projects such as
AudioTool which proved
that web audio projects can be as accessible as native and reach
some level of "professional" audio. (whatever that word means, for
me it is related to audio quality / stability / latency)
Another criticism was mainly associated to the fact that you
could not use Fragment to go along your day to day DAW as a plugin,
this is kind of important nowadays since digital music peoples have
a DAW / software that they use daily and associate any kinds of
instruments or effects to it through a standardized plugin
system.
I don't think this would works with Fragment as it is akin to
a standalone alternative DAW / performance tool already than an
instrument, it is a tool of its own with graphics / code being a
major part of it, i doubt it would works in tight integration, i
can imagine some parts to be used as a VSTi but it would then
become just like any other synthesizers which was never the point,
it would also induce quite a lot of development / maintenance on my
part that i was not interested with.
The web tech stack came with many challenges regarding
real-time audio processing with many black boxes to deal with
(dealing with plenty abstractions), the audio issues were all
addressed by moving the audio part to a native application, this
part could become a plugin of its own but there is little interest
in doing that as it don't bring anything new that VSTi brings
already.
There was many advantages of the web tech stack though : ease
of development, faster iterations, flexibility (UI etc.)
Anyway, i never thought of Fragment as a professional tool, it
is just some toy / oddity / experimental synth / DAW with a "what
if ?" concept, it can be used professionally i guess but it was
never meant to.
Fragment can still be used alongside a DAW the old fashioned
way, many of my videos were made with Renoise DAW being used to compose
(sending MIDI events) and apply effects.
There was also some criticism on the lengthy QA videos but the
point of these videos were just me QA testing my project and having
fun with it as well perhaps in goofy way sometimes because i quite
sucks at playing an instrument !
Conclusion
As a synthesizer / audiovisual environment
I think of Fragment as a maximalist takes of the
oscillator-bank and filter-bank concept, a big what if ? i took the
original concept and pushed it as far as i could, the result is an
experiment of sort; massive amount of oscillators and filters
driven by a big matrix of on/off switches triggered by GPU
accelerated code.
It can do all sorts of noise, i just scratched a tiny amount
of what is possible with it i believe but its main issue is its
bulkiness with lots of intertwined tech that is sometimes poorly
related, this makes it quite unfriendly to most peoples that would
be interested, it have a very steep learning curve (graphics /
audio programming) and the web stack / audio server also adds a lot
of burden although i think it works reasonably well for all it
does.
It is alright if ones use shader inputs with small amount of
code and stay with sound synthesis types which does not require too
many parameters (eg. additive synthesis, FM, wave-table ?), in this
way i can see it as an interesting platform / companion for sound
design, ambient stuff, experiments etc. it can do quite a lot of
cool stuff with a stock shader and some inputs.
On the audiovisual / performance side i didn't do much with it
so i don't know how far it can go but i believe it is where it
shines, especially with the desktop capture or webcam feature which
allow the outside world to interact with Fragment with minimal
setup / knowledge, some of my ideas were things such as some kind
of prepared lights show, making up some kind of organic "live
composition", the other cool thing is to be able to add visuals
(generated or playback) and mix them live.
Even though its inner working has a maximalist approach the
synthesizer interface is very minimal and i love its cold
presentation as a black "monolith", a big black opaque canvas which
feels whatever is sketched on it and spout it back through
speakers, this was also my original feels when i first watched pics
or videos of the ANS synthesizer
which is quite a cold beast.

ANS synthesizer, ~1957 photo-electronic musical
instrument
As a composer tool i think vector graphics approaches likes
HighC or UPIC are better
concepts since they have a thoughtful / elegant symbolic aspect
whereas Fragment is more free-form, there is a good explanation of
this on the HighC
webpage.
As an audio editor it is not quite there yet due to relying on
straightforward additive synthesis instead of manipulating the
spectrum directly and do an inverse transform, this result in a
diminished audio rendition so there is much better image-synth to
do that such as PhotoSounder but it could be
addressed with some more development i guess.
As a Shadertoy like
As an education platform
There is perhaps some use cases for the education sector due
to the collaborative aspect but this was never tested.
Conclusion
It was an interesting and formative experience to tackle a big
project like this all alone, also was a good approach to learn all
kinds of in depth details about audio, WebGL and real time audio
software architecture, going for a simple additive synthesizer up
to the architecture of a DAW with effects chain, modulations and
implementing many well known sound synthesis algorithms.
Nowadays i prefer minimalist approaches which can be as
effective and fun without a big bulky all in one environment that
weight quite a bit in term of maintenance and usability.
The audio server is a part that is quite relevant to my
opinion and could serve for other products, it could be interesting
to hack on or study because it is simple architecturally and still
has most features of a basic DAW / synthesis platform; it can adapt
to the embedded world easily, has good performance and its Faust
capability can be leveraged to make it produce any sounds.
Even though still unfriendly to most i still think Fragment
can be useful, it has matured and has huge amount of flexible
features for an image-synth. (or even a Shadertoy clone)
It is also quite fun as a conceptual noise-of-all-kinds
software and its unexplored performance aspect may be interesting
to reveal as well.
back to top
