Writing a primitive Forth in JavaScript
Contents
Introduction
What is Forth ?
Forth
is a typeless highly reflective
stack-oriented
concatenative
programming language created by Charles H.
Moore often used in embedded systems due to heavy minimalism
and flexibility.
This language features a minimalist syntax with identifiers
(called "words") separated by spaces.
It use Postfix
notation by default and features some base words (primitives)
that the user compose to build programs.
Forth has been historically used by calculators,
video games
(also as a scripting language), some 8-bit computers and
in many embedded systems. (space
industry, firmware system
etc.)
Motivation
This article is mostly an introduction to a
set of articles about building a baremetal Forth
based operating system. All of this is loosely related to my
Moving
to lower tech article and also influenced by code golf
programs.
Initial motivation was to experiment with
a straightforward Forth implementation as an introduction to
programming languages.
This prototype was later ported to ARM (RPI
0) based on all the acquired knowledge with minimalism still a
goal.
The ARM implementation was then expanded to a slightly more advanced ARM
Forth dialect / compiler which evolved to a personal baremetal
computing environment focused on a blend of minimalism and
usability.
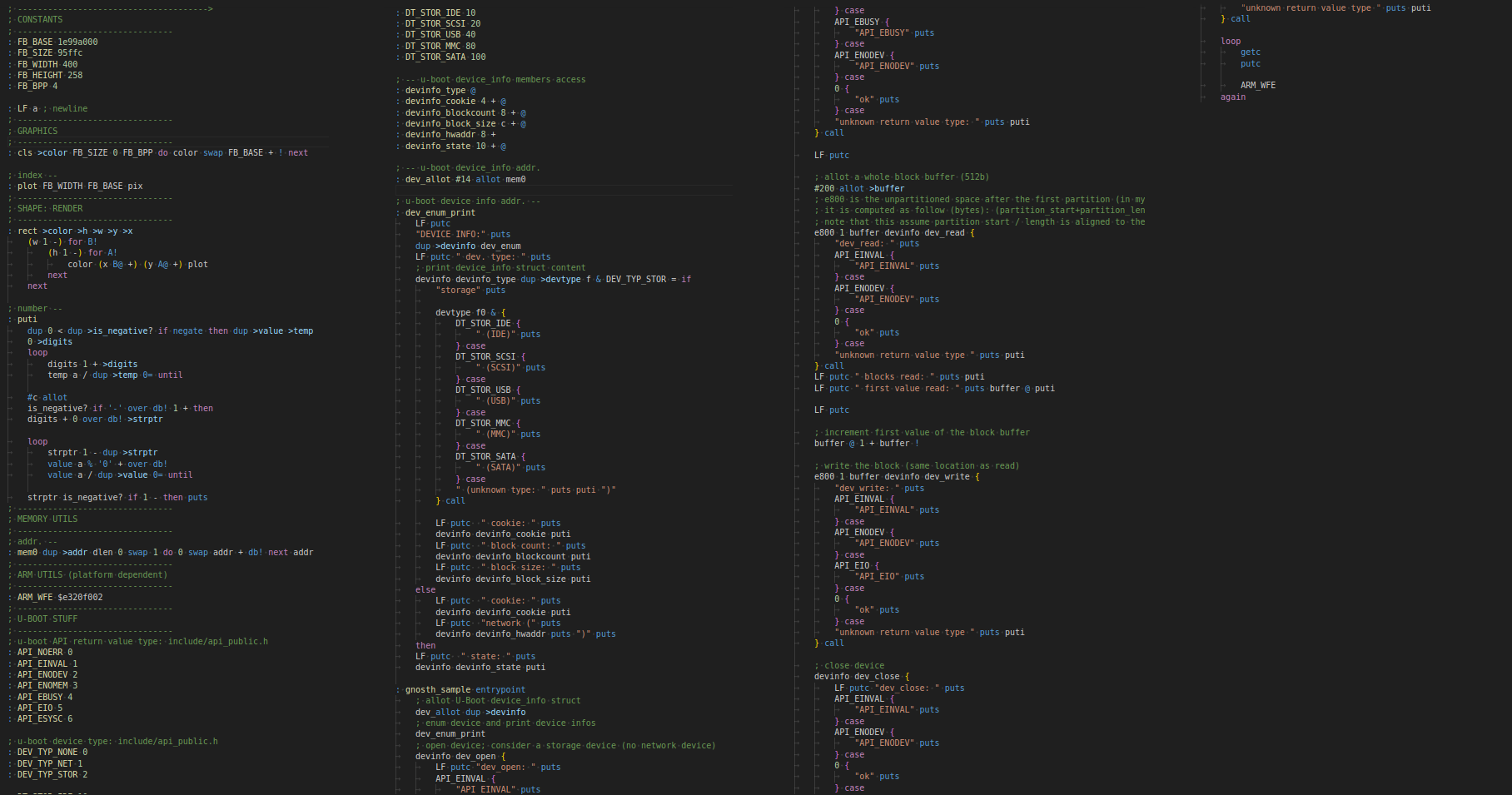
a full example program of my ARM Forth dialect
(~70 primitives not counting syntactic sugar)
Resources
A helpful starting resource to understand Forth was the
write-up
of jsforth by
jborza but most importantly
Starting Forth
and Thinking
Forth by Leo Brodie followed by JONESFORTH
low level x86 implementation along with Gforth to experiment
with the language,
Moving Forth
series was later useful on details for a low level
implementation. (most useful to me was the threading technique
comparison which made me chose a Subroutine Threaded
Code technique)
Some other resources :
- Forth Tutorial
- Forth Primitives
- StackFlow
Forth
- Forth
History
- The Language That Writes Itself
- XXIIVV page about Forth
As for videos, i quite like the Silicon
Valley Forth Interest Group YouTube channel.
Prototype
This prototype is a primitive Forth interpreter implemented in
JavaScript, it is not fancy and try to use straightforward bits of
JavaScript, it make use of the p5js
framework and has a graphical CLI emulation instead of simple text
output.
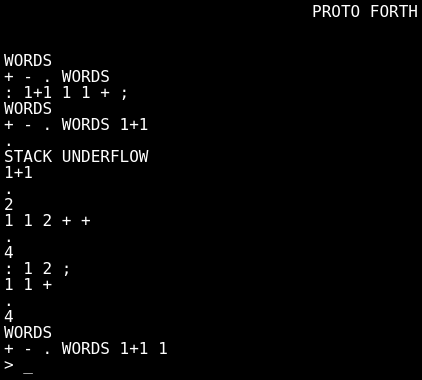
the Forth proto, ':' define a new word, ';'
close the definition, a word is a composition of other words
It support these words :
- : switch to compile mode
- ; switch to interpreter mode
- + add two numbers
- - subtract two numbers
- . show stack top content
- words show defined words
It try to parse unknown words as numbers, they are pushed to
the data stack if successful.
Practicality note :
The prototype is missing a few primitives that are required
for a practical Forth implementation (stack manipulation words
etc.) for the sake of conciseness but Forth concept is fully there,
primitives can be trivially defined later on like the existing ones
to complete the language by following the standard or making them up to
build a personal dialect / match a specific problem domain.
My most advanced Forth dialect (see screenshot above) which is
compile only has ~70 primitives of which ~15 are I/O related and
~10 are only there for extra speed, it does not contain '.' nor
'words' primitive compared to this prototype.
Also note that there is incredibly small implementation of
Forth such as sectorforth or
milliForth,
they show the highly reflective features of Forth by bootstrapping
a fully featured Forth out of a minimal set of trivial primitives
(~10 implemented in assembly) in less than 512 bytes.
To go further down the rabbit hole there is also a 3 instructions
"Forth" or even a
2 instructions one !
Proto Forth breakdown
Here is a breakdown of the Forth prototype without CLI
emulation.
The code roughly match a low-level implementation which is why
i use an array of characters for the words (i call them tokens
here) instead of a string type, implementation may be simpler with
higher level constructs / data types of modern programming
languages.
Data structures
A Forth implementation in a high level language only needs two
data structures :
- a data stack to pass data between words, my prototype has a
single data type : numbers
- a words dictionary which is where predefined words (also called primitives) go into along with user defined words
Dictionary words contain a list of functions and a boolean to
indicate how the word must be interpreted.
A low level implementation additionally add a return stack and
the dictionary is usually implemented as a linked list with room
for word flags / word length plus code body, an optimized version
might prefer a hash map for the dictionary to speed up words
lookup.
let fmode = 0 // forth current mode;
0 for interpreter; 1 for "compiler"
let stack = [] // forth stack
let curin = [] // currently processed input
let words = [ // words list with predefined primitives
words
// t: token, f: token code as a list of functions, i:
immediate ?
{ t: [':'], // switch to definition mode (compile mode)
f: [(s) => {
fmode = 1
// consume next token and add it to
words list
let nextToken = ntoken(curin)
if (nextToken.length) {
words.push({
t:
nextToken,
f: [],
i: 0
})
}
}],
i: 0
},
{ t: [';'], // end definition mode (switch back to
interpret)
f: [(s) => {
fmode = 0
}],
i: 1
},
{ t: ['+'], // plus
f: [(s) => {
if (s.length < 2) {
return 1
}
let a = s.pop()
let b = s.pop()
s.push(a + b)
}],
i: 0
},
{ t: ['-'], // minus
f: [(s) => {
if (s.length < 2) {
return 1
}
let b = s.pop()
let a = s.pop()
s.push(b - a)
}],
i: 0
},
{ t: ['.'], // print the stack top content
f: [(s) => {
if (!s.length) {
return 1
}
addToLineBuffer(s[s.length - 1] +
'')
}],
i: 0
},
{ // print all defined words
t: ['w', 'o', 'r', 'd', 's'],
f: [(s) => {
let lwords = []
for (let i = 0; i < words.length;
i += 1) {
lwords.push(words[i].t.join(''))
}
addToLineBuffer(lwords.join(' ') +
'')
}],
i: 0
}
]
Note how the compile mode is defined as a primitive, ':' start
a new word definition and directly parse the next word then add it
to the words list, ';' switch back to interpreter mode.
Word search
A Forth simply parse input words and look for them into the
dictionary so we need a way to search words :
// find token (word) in
dictionary
function ftoken(token) {
for (let w = words.length - 1; w >= 0; w -= 1) {
let word = words[w]
if (token.length === word.t.length) {
for (let t = 0; t < token.length;
t += 1) {
if (token[t] !==
word.t[t]) {
break
} else if (t ===
token.length - 1) {
return
word
}
}
}
}
return null
}
This searches the word backward to ensure that the most
recently defined word takes precedence, allowing newer definitions
to override older ones.
It is not mandatory to search backward but it helps supporting
dynamic and iterative development, it also has a lookup speed
advantage for the recently defined words.
Word call
An utility function to sequentially call all the functions
associated to a word, this is necessary to run user defined words
(which are a composition of words), each of these functions may
return an error code that is also handled to provide some feedback
about the execution state :
// execute word code
function wcall(word) {
for (let i = 0; i < word.f.length; i += 1) {
let r = word.f[i](stack)
if (r === 1) {
addToLineBuffer('Stack
underflow')
return 0
}
}
return 1
}
Word parse
This consume an input string and collect characters until a
white-space is detected (a "word" in Forth is any characters
delimited by a white-space), collected characters are then returned
:
// consume input string until a
white-space is reached then return consumed / collected
characters
function ntoken(t) {
let token = []
let c = t.shift()
while (c && c !== ' ') {
token.push(c)
c = t.shift()
}
return token
}
Interpreter (entry
point)
The interpret function is the entry point of the
interpreter / compiler, it is called with the input string after
the RETURN key is hit, it call the tevaluate() function for
each words parsed by the ntoken() function :
function levaluate(s) {
curin = s
let token
while ((token = ntoken(curin)).length) {
if (!tevaluate(token)) {
return
}
}
// should output "ok" in a standard Forth at this point as a
simple feedback mechanism
}
Word evaluation (forth
core logic)

Forth core logic in a nutshell shown as pseudo
code (taken from a Reddit post)
The evaluation code is straightforward but the
"compile word" step may be confusing at first although it is
incredibly simple : in compile mode ':' all evaluated words are
added to the functions list of the newly user created word (the
latest word of the dictionary) unless the immediate flag is set,
this generate (compile) the new word body code which is just a
composite of other words functions. This basically allow to
extend the dictionary with new words.
The same idea is applied when a number is found
in compile mode except that it generate the call of a function that
push the number since it is not really practical to have a
definition for each numbers.
In compile mode the immediate flag of a word
execute the word immediately when set, it act as a parameterized
macro
system and is useful to implement ';' for example to switch the
mode back to interpreter mode, it act as a way to alter the
behavior of the Forth during the compile stage and is useful to
implement many language constructs such as conditionals etc. it can
act similarly than the C preprocessor although it is way more
powerful. (it is a part of the reflective
nature of Forth)
// token ('word') evaluator
function tevaluate(token) {
let word = ftoken(token)
if (word) { // process word
if (!fmode || (fmode && word.i)) { // call
word code when forth mode is either interpreter or compiler /
immediate mode
return wcall(word)
} else { // compile mode (add word code to the
most recently defined word)
let tail = words.length - 1
words[tail].f =
words[tail].f.concat(word.f)
return 1
}
} else { // unknown word so try to parse it as a number
let i = parseInt(token.join(''), 10)
if (isNaN(i)) { // not a number so output a
feedback message, rollback if in compile mode
if (fmode) {
fmode = 0
words.pop()
}
addToLineBuffer(' Undefined word ' +
token.join(''))
return 0
} else { // a valid number ?
if (fmode) {
// append function which
wrap stack push
let tail = words.length
- 1
words[tail].f =
words[tail].f.concat([() => { stack.push(i) }])
} else {
// push regular
number
stack.push(i)
}
return 1
}
}
}
And voilà ! All of this implement the core concept of Forth,
it lacks few primitives such as I/O and stack operations such as
drop, dup etc. to be really useful as it looks like a fancy
calculator right now but they are mostly trivial to add just like
it is trivial to extend the language by adding words to the list, a
complete Forth implementation has words for loop constructs,
conditionals etc. all the elements of a programming languages can
be defined in the same way.
Postfix notation
Postfix
notation may looks rough but i tend to think that it is mostly
a question of habituation, Infix is perhaps
easier to read sometimes but involve slightly more complicated
parsing.
A way to makes Postfix notation more readable is by allowing
parentheses to group elements, they would be mere syntactic
decoration compared to Infix but might increase the readability in
some situations. The other way involve an Infix to Postfix
conversion step using an algorithm such as Shunting
Yard algorithm. (which was later generalized to operator-precedence
parsing)
Conclusion
This prototype was quite eye opening to me as i realized the
brilliance of Forth design / practicality while writing it, this
interpreter is a kind of virtual machine (a Stack machine
instead of a Register
machine) embodying minimal concepts of a programming language
with reflection
being a core feature, the prototype was akin to an extensible "OS"
shell / programming language combo in ~100 lines of code... and the
implementation journey was incredibly easy and lovely with
straightforward algorithms, it doesn't require an Abstract
Syntax Tree due to its syntactic minimalism for example, it end
up being a chosen series of cohesive and compact instructions that
one can flex for any use cases.
Some improvements for the prototype others than adding
primitives might be to bootstrap the
REPL in Forth with the reflective features (this only require a
few primitives) or generate low level code (or an intermediate
representation) for the primitives so that it is more akin to a
compiler.
Lisp
might be worth checking out as it is a slightly higher level
language than Forth but still stay compact and simple.
back to top
