ARM2 ~50 FPS height field rendering
This is a technical write up about my first
graphics program for the ARM2
8MHz Archimedes: a 3D height-field at 50
FPS.
This article also goes a bit beyond and show what
can be done (mode
7, floor-casting, volumes etc.) with the rendering method
presented here.
Summary
Few weeks ago i started programming for the ARM2, i decided to
do some graphical effects after being accustomed to the tools. (BBC
BASIC 5 inline assembly, RISC OS
API)
I decided to do a height-field, making some rough prototype in
p5js and then do the ARM2 implementation:

Acorn Archimedes, ARM2, 8MHz real-time
landscape (first version, ~900 onscreen 16x11 blocks)
The initial idea was to see how fast the ARM2 CPU
was by using a brute-force height-field rendering approach, how
many animated blocks making up a clean 3D landscape could i push at
~50 FPS, 320x256 resolution and 256 colors ? The answer is more
than ~950 real-time onscreen 16x11 blocks on a 1987 Archimedes with
a 8MHz ARM2 CPU! Note that there is also some screen clearing.
(+ FPS / OS calls)

Second version is slightly faster, ~1100
onscreen 16x11 with bitmap background on ARM2 MEMC1
Benchmark video
of the landscape running on ARM2 8 MHz, ARM250 (12 MHz, 16
MHz)
Height is altered / blocks are clipped in
real-time. (clipping is done in selected fixed width blocks when
they overflow on the left or right)
It is possible to move in any directions on the
landscape although there is no code for yaw rotation.
This is quite heavily optimized for the cache-less ARM2 CPU
with heavy loops unrolling and duplicate maps data resulting in a
~500kB binary for 128x128 maps. The color-map and height-map come
from Comanche: Maximum Overkill. Some data are compressed with
LZ4.
ARM3 with its cache would have a hard time with
all the loops unrolling so the code is not adapted to ARM3+ CPU, it
can be converted easily though.
Here is a summary of all the optimization methods
i applied:
- loops unrolling
- modifying the PC directly to
jump
- points position (the flat grid) ordered by depth are preprocessed so the Y position is the only thing that needs to be altered to form the height-field
-
- the preprocessing goes as far as embedding the screen address
for the two screen banks on startup (so there is actually two set
of points in memory due to double buffering), points are ready to
be drawn without additional processing
- points data also contain U/V data
(interleaved) and there is a preprocessing step to embed the maps
address (same idea than points position)
- the preprocessing goes as far as embedding the screen address
for the two screen banks on startup (so there is actually two set
of points in memory due to double buffering), points are ready to
be drawn without additional processing
- data are interleaved (points data, maps data) so they can be
fetched in a single instruction: i fetch 3 points data at
once
- maps data are duplicated in memory as a scroll optimization,
moving on the landscape is then done with a single instruction for
each points, the out of boundaries check is done outside the
rendering loop
- overflowing blocks (at the bottom) are culled and then
clipped
- heavy use of ARM block copy instructions (ldmia / stmia)
- fit as much data as possible into registers
- skipping screen rows
- about half of the screen is left uncleared, this save cycles
and help to hide gap due to low points density (gaps may appear on
high height difference)
All of this result in a very simple rendering code albeit with
massive code generation and code for all the preprocessing
stages.

same as above with different map (prototype
version)


16 colors version, 8x10, ~2000 rectangles,
first version
The 16 colors version is about twice as fast /
use 2x less memory, it writes a single word which amount to 8
pixels at once, it also fetch 5 points at once. It can draw ~2000
rectangles. Screenshots don't look that good due to raw conversion
of the assets to 16 colors, it also uses early code with less
accurate perspective.
Memory usage
Program memory usage of the 256 colors version is
~500kB with 128x128 maps. For simplicity there is no data loaders
so the program binary embed all the data (even compressed ones)
which result in about ~50kB overhead, ideally the data would be
loaded / freed dynamically as needed.
There may be many improvements for memory usage,
about 100kB can be gained at the expense of some CPU cycles by
using a single landscape map data, i don't think this would affect
performances much. Maybe the amount of generated code can be
improved as well.
Memory usage would be much lower (more than
100kB) without loops unrolling. ARM2 code density is not
great.
With 256x256 maps it goes to more than 1MB
uncompressed.
Scaled dots landscape ? Fake voxel heightfield ?
Dots landscape ?
A dots landscape is a simple well-known retro graphical effect
where dots are positioned on a plane (with 3D projection)
and the points Y position is altered by a height-map, coloring
the points based on their height (as seen below) or a color-map is
also possible to make it nicer, this was popular on 80s computers
like the Atari ST or Amiga, i actually started by implementing a
dots landscape:


the points generator with points vertical
position altered by a noise function (p5js prototype)

same with more dots and animation (p5js
prototype)
As you may see the only change is the points
vertical position and shading, there is no changes on the
horizontal axis, this can be used as an optimization by precomputing the
grid.
Rendering speed may be easily controlled by
tweaking the loop step of the grid, this reduce the number of
points on the grid.
Scaled ? Fake voxel ?
A brute-force idea to make it 'voxel-like' is to 'scale'
each dots (i.e., turning them into squares/rectangles) so there is
no gaps between them. This is the core idea of the algorithm. It is
a brute-force approach because high amount of (small) rectangles is
needed for high quality landscape.
Points also needs to be rendered from back to front now in
order to solve visibility issues. (painter
algorithm)


Same as above with 8x12 rectangles instead of
dots, height based shading (left) and color-map based shading
(right), iteration step: 2 (p5js prototype)
The issue of this rendering method is the gaps which may
appear between rectangles, especially noticeable when the height
difference between points is high and the rectangle is too
small.
There is several ways to hide the gap such as increasing the
points density or rectangles size, the computing power required is
higher however. Height range can be decreased as well.
Some gap are actually okay if the screen is left uncleared for
the parts of which the landscape cover, gaps will be filled and
most visual artifacts will be unnoticeable, this also help reducing
rectangles size and amount of screen clearing to do which may be
CPU intensive on 80s hardware.


Gaps appearing on slopes due to rectangle size
(left) simple fix by not clearing the screen (right)
Not clearing the screen is not a perfect solution
though and some other visual artifacts may appear (especially on
the bottom part of the screen due to lower points density, not seen
in above examples), it require some tweaking for an acceptable
result.
The rendering method presented in this article use rectangles
of fixed size and was chosen because it is quite effective on the
Acorn Archimedes due to fast ARM block copy instructions (ldmia /
stmia), block copy instructions are able to load / store the ARM
32-bit registers in a single instruction. This means that drawing a
16x16 pixels square in 256 colors mode can be done in 31
instructions which equals to ~127 CPU cycles. (in 256 colors mode a
pixel = one byte thus storing a register = 4 pixels at once and 8
pixels at once for 16 colors mode etc.)
Main disadvantage of fixed size blocks is that
many cycles might be wasted on overdraw.
Beyond
This rendering method can draw textured planes as-is easily by
dropping the height component. This could be useful in 2.5D
platform games for old-school platforms if ones imagine them tiled
and perhaps layered (perhaps something like Bug!), could also be used
as a cheap way to do SNES mode 7 style games. This
show how 'mode 7', ray-casting/floor-casting and early 90s
height-field rendering are pretty much related. :)


Textured plane rendered with the same method
(p5js prototype)
This rendering method can also draw volumes as
easily (ie. voxel) by just stacking
the planes, drawing them multiple times with slight offset applied
to the vertical position. There is many possibilities to make this
fast with many features on retro hardware, the volume resolution
will probably stay low but is sufficient for many
effects.

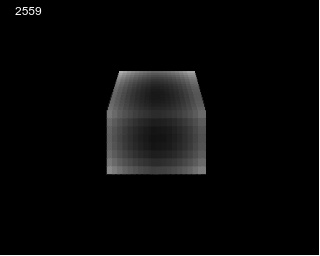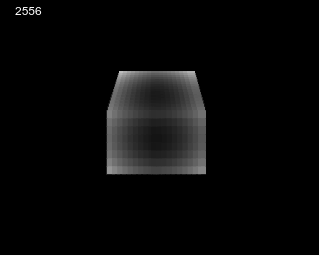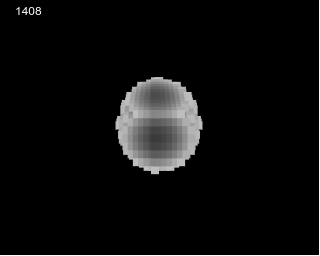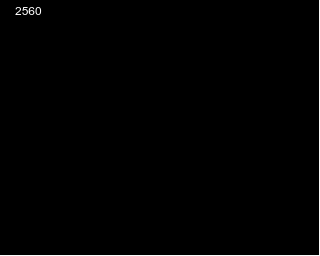
40x64x8 volume made of 8x8 blocks showing a
sphere that shrink / expand, can be done on ARM2 8Mhz at 50Hz using
the same method as presented here (p5js prototype here)
Square grid vs projected grid
Points of the grid in the screenshots above are projected
mainly for aesthetic reasons (and because that was my first
approach for the landscape), ones could also use a square grid
which has many optimization advantages over a projected grid: it
fit the screen perfectly so don't need to clip sides, square grid
have equal spacing between points, clipping / culling is
unified.
Points are also related vertically with a square grid, this
allow to perfectly fit rectangles to the grid so 100% coverage
without overdraw, also means you can have high height scale factor
without issues because the projection will be done in UV space
instead of screen space.
Square grid also allow easy
occlusion culling by drawing front to back and using a y-buffer
where highest vertical position is stored and checked.
Visual differences between projected grid and square grid are
few but noticeable, the projected grid will have less details near
the viewer (due to points density being lower) but farther features
will looks less blocky, slightly more organic. I still don't know
about the performances but a square grid may be faster sometimes,
it may have way more points than a projected grid though. Projected
grid rectangles needs to be scaled x2 or even x4 horizontally (vs
square grid) to cover grid gaps on the bottom of the screen due to
points density.
I still think a projected grid is an efficient approach on
limited hardware with fast block copy unless some heavy
optimizations is done with the square grid (eg. Transhuman/Pachinkoland
demo on Amiga OCS), i bet one could also implement yaw / pitch
rotation easily and make it very fast (even in case of volumes) by
adjusting the projected grid prior rendering with lookup tables,
doing it in multiple VBL to
amortize the cost of updating all points, would also needs depth
sorting i guess.
A fringe idea: If ones don't care about rotating their display
90° (why were they specifically oriented anyways ?) a very fast
rendering engine can be done on hardware with fast block copy, a
square grid and y-buffer. :) Ones could also find a way to rotate
the whole frame-buffer by 90° once the rendering is done, i don't
really know how fast would it be versus a conventional render
though but maybe it would be worth it on faster CPUs. Ones could
also imagine some kind of hardware that facilitate it by rotating
the whole frame-buffer before displaying it, on that topic i always
liked Alvy Ray
stream processor idea which would be able to rotate by 90°
cheaply by using a two-pass technique.


Projected grid (left) vs square grid
(right)
The projected layout may be more suitable aesthetically for
platform
games or strategy
games.
Rotation
Didn't implement optimized yaw rotation
on ARM2 but it works on the proto without much changes, it works by
modifying the height and colormap lookup code / computing the
rotation (it replace the ADD instruction), this might add a few
cycles on ARM2 but should still works at ~25 FPS on the 1987
hardware with the help of lookup tables to avoid the rotation
math.
An untested idea for rotation (and actually even scrolling)
would be to pre rotate/scroll a copy of the bitmap data at each
frames, the rotation/scroll would only happen on the view area
(which is rectangular) and is around 48x48 pixels for a 128x128 map
(as seen below, this of course depends on view/steps parameters),
this would takes some CPU cycles but there would be no
modifications to the rendering loop, it would perhaps free one or
two cycles (add and sub) as well in the main loop.

with rotation (p5js)
Rendering / ARM2 optimizations
Weak perspective projection
The first version of the grid algorithm was built with
fixed point arithmetic as i thought of computing the
grid on the ARM2 at first, i decided to switch to preprocessed
points data later on to match my real-time performances
requirements, i was also using a custom projection at first but
switched to weak perspective projection later on as it is actually
nicer and flexible in most cases and required less points in the
end.
The camera setup can get pretty close to the one in a game
like Comanche: Maximum Overkill (1992).
Sides clipping

This was solved by detecting the blocks that overlap the edges and
fixing their position to a 4px grid in the tool that generate the
points data, the points on the Archimedes are then drawn using
different width (4, 8, 12 or 16px). 4 is the smallest block width
because it fits into a word on the Archimedes.














Atari 800



Old prototype (p5js)

Conclusion
Here is the basis of the points generator algorithm (p5js):
function setup() {
createCanvas(320, 256)
rectMode(CENTER)
noStroke()
fill(255)
}
// note : for a square grid just swap xx and yy by x and y,
basically the projection will be done in UV space vs screen
space
function draw() {
background(0)
let points = 0
let stepx = 4
let stepy = 4
// might have to play with the extent of the loops here to
fill the screen
for (let y = 0; y < height / 2; y += stepy) {
for (let x = -width / 2; x < width / 2; x +=
stepx) {
let h = 1 // replace by noise
function or height-map sampling
let xx = x / (height - y) *
height
let yy = y / (height - y) *
height
// color the rectangle based on a
color-map by using x/y as u/v coordinates like:
// const mapIndex = (floor(x +
width / 2) + floor((y + frameCount) % colormap.height) *
colormap.width) * 4
// const red =
colormap.pixels[mapIndex + 0] // get red color component
// etc.
// the same index can be used for
sampling the height-map
// and multiplying, dividing x and y
in the map lookup allow to adjust the 'camera' FOV
// 'pitch' can be adjusted by
modifying the constant for: yy / 2
rect(width / 2 + xx, height / 2 + yy
/ 2 + h, 2, 2)
points += 1
}
}
fill(255)
text(points, 16, 16)
}
Visibility
All points of the grid are preprocessed in a p5js tool, the tool basically run the
landscape code for some frames and store all the rectangles which
will be visible at some point in an array along with metadata like
UV, position
and width of a block. The generated data files are downloadable and
are used by the Archimedes landscape rendering code.
Preprocessing
Data are preprocessed on the Archimedes before rendering,
embedding the screen address and map address offset into the points
/ UV data so they can be used right away without additional
computation.
Sides clipping
Fixed size rectangles may overlap the edges of the screen and
may produce visual artifacts as can be seen below.
16px width blocks overlapping the left side
piles up on the right side
The first implementation was real-time and a bit unreadable as
can be seen here, it
used a branch
table and modified the PC directly to
jump to the appropriate block code.
{kind=link}
Points horizontal position never change though so all the code
of the first implementation is unnecessary... clipping can be done
efficiently by selecting / generating the right block draw code at
compile time for each points, this result in a much simpler /
faster / smaller implementation with CPU cycles gain compared to a
no clipping approach !
Culling / clipping bottom blocks
Culling / clipping bottom blocks is needed because blocks can
also overflow the bottom part of the screen which actually result
in a crash unless many screen banks are
used.
The sides method wouldn't work here because the rectangles
vertical position is altered in real-time.
The first implementation had a simple culling / clipping combo
which was implemented as two instructions per rectangle, checking
the Y position against the screen boundary and jumping to the next
rectangle when the block overflow. I was using 4 screen banks for
clipping, this was a cheap trick to make the bottom blocks appear
clipped by allowing the ones partly visible to overflow the bottom
part of the screen.
Found a solution later on to only use 3 screen banks, the
first bank would have thrown some blocks to the second ones but
this could have been mitigated by clearing the top part of the
screen (or drawing the sky) before rendering the second bank, it
was the same result with very small performance penalty and better
memory usage.
Skipping screen rows
Going further with optimizations

Proper clipping of the bottom blocks
I was not satisfied with the clipping method of the first
implementation, it had the advantage of being very simple code-wise
at the expense of high memory usage (4 or 3 screen banks instead of
2) and wasting some precious CPU cycles.
The current implementation does proper clipping (lines outside
the screen are discarded) and don't use additional banks, it use a
duplicate of the block draw code with 2 instructions added after
each lines to check if the current line overflow.
The clipping code use a subroutine call to make the code
simpler, it is good enough as-is but could be optimized further at
readability expense. I don't think the cycles would be worth
though.
Skipping screen rows
The second version can skip screen rows, this provide a huge
boost to performances at the expense of looking more blocky if the
step is high, it is generally fine for a step of 2 and begin to be
very noticeable at a step of 4.
The way it works is by fixing all the blocks to a grid
(vertically) which is the size of the wanted step then i just skip
one of two (or more) lines of each rectangles and copy the lines of
the screen as needed outside the main rendering loop.
It is fast because the lines copy uses unrolled loop plus ARM
block copy instructions (ldmia / stmia).
Going further with optimizations
Ideas that may provide some boost:
- adding some sort of
LOD by decreasing landscape resolution for the farthest
points
- the height / color lookup data could be provided as 'data as code', there would be no memory lookup to gather the maps information, just code like some jump and `mov`, still unsure how much gain this would provide since the actual lookup is already efficient (done with a block instruction) so it doesn't require much cycles to execute (~6 cycles), this idea may also be severely limited by the ARM2 instructions set due to constrains on immediate value encoding
- drawing the bitmap background can be slightly more efficient by taking into account screen rows skipping
- there may be some optimization to do with rows skipping such as
copying one frame on two, this may produce visual artifacts
though
Some more ideas on how to optimize further if the view /
camera path is constrained:
- don't generate code for points elevation if the point never does for the chosen view / camera path, require to generate some kind of points height list and skip the instructions as needed (~2 cycles gain / rectangle)
- don't generate code for points culling if the point never overflow the bottom part of the screen for the chosen view / path, require to generate some kind of list and skip the instructions as needed (~2 cycles gain / rectangle)
How efficient it is ?
At 50Hz 256 colors mode, the second version of the code can
draw ~1100 16x11 rectangles per frame on the 1987 Acorn Archimedes
with MEMC1. (skipping one of two screen row)
The theoretical maximum
of cycles per frame on a 1987 Acorn Archimedes is a bit less than
160000 cycles.
The most critical part
(and the ones i consider the most efficient) is the rectangle
rendering code which alone consume on average 98 cycles (for 16x11
block) plus ~38 cycles added by the DRAM controller (every 4
words).
So, if we scale this
up we can theoretically render ~1160 rectangles / frame at 50Hz
with that code alone.
For a more accurate
answer i made some simple test with that code and came up with
~1200 rectangles / frame at 50Hz. This give an estimate of the theoretical
limit at 50Hz.
The rectangle rendering
code alone is of course not sufficient to draw a real-time
landscape, there is at least one lookup for the points data,
texture map and elevation data plus some instructions in between,
this amount to approximately 20 more cycles / rectangle, clearing
half the screen efficiently is about 10k cycles as well, double
with a bitmap and skipping/copying lines of the screen is about 20k
cycles as well.
So, it is nearly at its
peak efficiency already.
The numbers are a rough
estimate and don't take into account clipping, culling and main
code. Clipping may add a small cost sometimes because of the use of
a subroutine.
A slide i like to refer to when it comes to
timings on the ARM2 (from ABug 05 Sarah Walker
talk)
Render loop code
Below is the BBC BASIC function which generate the
ARM2 render loop code (first implementation with multiple screen
banks) that is executed each frames. It is small with ~20
instructions for each points, about half of which is duplicate
block copy instructions to render each lines of the
rectangle.
Would be simpler without code generation!
The code with improved clipping (final version) is
slightly more dense but is about the same for fully visible
blocks.
Download
Most recent ARM2 assembly sources + binary and associated
JavaScript files to generate the data can be found here.
Can also be found here.
Just put all the files into hostfs Arculator directory and
either run the binary directly (!bin file) or run
!assemble to build the program. This include
!bass which is my BBC BASIC V aided framework /
assembler.
On real RISC OS you may have to modify the files type (BASIC
for code and Absolute for binary).
Sources for the 16 colors version can be found
here (first version)
First 256 colors version sources / binary can be found
here.
Tools
Two p5js (JavaScript) tools are included, one is used to preview / generate data and the other is a simple 256 colors bitmap export tool which is used for the background.Use p5js for the tools, you
can just edit/run the code within the online editor.
The landscape generator is quite flexible: everything can be
done inside the tool without having to fiddle with assembly, this
include all parameters which control the landscape quality /
resolution and geometry.
The data generated by the generator can be used directly by overwriting the existing files and assembling again.
The data generated by the generator can be used directly by overwriting the existing files and assembling again.
Heightfield rendering in retro demos
Here is some example of height-field rendering demos on
roughly similar hardware (click on images for YouTube video /
Pouet link):
Archimedes (ARM2, ARM250, 1987)
Horizon by The Master (2019)
ARM2
Archiologics - Jojo (1996)
Quite nice 'voxels' stuff although not really
landscapes, work best on ARM250 (i think)
Xtreme (1995)
ARM3 but great landscape with distance fog and
very detailed objects
Amiga 500 (OCS, 1987)
Transhuman/Pachinkoland by The Electronic
Knights (2022)
Very stylish and fast landscape, best i have
seen so far, lots of tricks probably :)
Planet Rocklobster by Oxyron (2015)
HAM mode, great
details and colors, fog but with lines skip and low
distance
Electrons at work by The Electronic Knights
(1998)
Great landscape with yaw rotation
VergeWorld: Icarus rising (game)
Blocky and very short draw distance but works
well enough
Rampage by The Electronic Knights
Short distance / height, fixed direction and
few details but 1994
Atari ST (1985)
Out A Time (2024)
very cool landscape with some objects
The World According to Nordlicht (2015)
Great and smooth landscape, best i have seen on
this platform
Suretrip 2 - Dopecode by Checkpoint
(2009)
Short draw distance and weird projection but
detailed landscape
Rumpelkammer by STAX (1999)
Detailed but short draw distance
Module Compilation #11 - Magrathea
(1996)
Atari 800
Arsantica 3 by Desire (2016)
Voxel 2k16 (2022)
Slow but cool nonetheless (4x3 res. + fake
shading)
Reditus by Zelax (2004)
Old prototype (p5js)
First early attempt at a landscape, initial
target was Sega Master System but i actually never ported it,
mostly use the same method as presented here with a custom
grid:
Conclusion
This was fun to optimize, it was all done within Arculator
(Archimedes emulator) with bundled RISC OS apps (!edit and BBC
BASIC) on 1987 emulated hardware, like a real 80s development
environment (also included slow compile time and difficult to debug
bugs !), doing the prototyping in JavaScript helped to iterate a
lot faster though.
The landscape code is quite simple and flexible and could be
used for games / demos. The advantage of doing the brute-force
landscape approach is the amount of parameters (rectangles count,
rectangles size, grid layout etc.) to tweak to improve the quality
of the landscape (can make trade-off easily), it is also an
efficient approach for the ARM2 due to block copy
instructions.
It could be used to do textured planes made of tiles (a bit
like Star Fighter 3000 game but more restricted) by dropping the
height parameter.
May also be used to draw objects with some changes, bit like
point
cloud.
For games, decals or height modifying stuff (Magic
Carpet anyone ?) can be done easily and fast by poking into the
maps.
Also wonder how textured blocks would looks, wouldn't be hard
to adapt, maybe it would look like those 80s/90s 3D games with many
scaled sprites.
There is not much cycles left as-is on ARM2 to stay at 50 FPS
(without tweaking / changing screen mode or going for lower
quality), on ARM250 (12MHz) there would be more cycles available
though.
back to top
