Acetaminophen - RISC OS 256 bytes
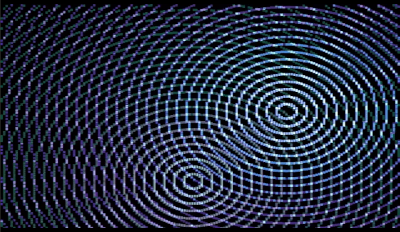
640x480 version
My first Acorn
Archimedes / RISC OS intro with two versions :
- mode 13
320x256 256 colors for Acorn Archimedes
- mode 28 640x480 256 colors for VGA monitors which was shown
at the party (running on a Raspberry PI Zero)
The first version works best on ARM3, CPU cache probably help
a lot, works fine on ARM2 also albeit slower.
The initial idea was lit off by Optimus with his 2023 512
bytes Ibuprofen entry
for Acorn machines which show an effect with multiple circles
circling around and producing Moiré
pattern, the effect originate from the Paracetamol Amiga
demo (1990).
I thought it would be cool to do that effect with minsky
display hack (an algorithm i am experimenting with since
some times) so i built a prototype in JavaScript but had no plan to
do something with it, i then stumbled on Optimus entry again and
took the challenge to do it in 256 bytes on Acorn hardware.
I was mainly motivated by the thought that ARM architecture
with its barrel shifter / 3 operands instructions would be at ease
with minsky algorithm even though each instructions takes 4 bytes,
also wanted to do code golfing on late 80s hardware since a long
time so this was the perfect opportunity!
Minsky display hack is also used for the circles animation, it
emulate sin / cos in ~4 instructions !
I started with high resolution modes at first (1 bpp / 2 bpp)
with a buffer (instead of computing the circles directly) but it
was uglier and slow so i switched to mode 13 and computing circles
in real time, lower bits per pixel have a bytes cost to handle
pixel perfect plotting, you either have to hold four copy of the
buffer or compute the adjustments directly which also cost some
instructions.
Since mode 13 is not supported on modern monitors i did a
second version with mode 28 so the intro could works on VGA
monitors and i could record the output as well since i don't have
any Acorn machines.
The two versions slightly differ in style, the mode 28 version
draw the circles with some sort of additive blending and the mode
13 version draw the circles with a "drop shadow", the drop shadow
was easily done by modulating the color of the circle "atoms"
(pixel blocks) as its height increase, this is a bit faster on
early ARM because there is two RAM lookup instead of three.
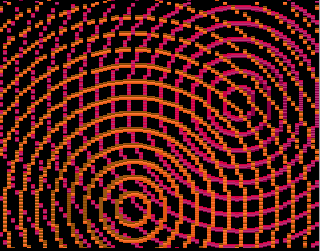
320x256 version
84 bytes is taken by RISC OS API calls for screen setup,
double buffering setup, vsync and clean exit with escape key, this
doesn't help for code golfing but it can be reduced by not using
double buffering or vsync for example but will looks uglier.
This intro could probably be done with RISC OS API by using it
to draw circles and do the masking, i don't know how much code
would that need and i am not sure about the speed either.
The code is tight on registers, the circle loop use all 14
registers and the remaining registers are used for calls.
It doesn't use compression but CodePressor
(ARM code compressor) can be used to gain some bytes.
The mode 28 version is slightly lighter because i removed the
two instructions which allocate screen memory for double buffering,
it seems unneeded on RO5 / RPI zero and anyway pre-RiscPC can't
double buffer mode 28 due to VIDC limits so i guess it is an okay
trick.
Had plenty fun in the end and ARM proved to be adequate for
code golfing (despite the high bytes cost of the RISC OS API / ARM
sometimes), what helped a lot :
- 3 operands instructions
- all instructions can be conditional
- multiply and accumulate instruction
- barrel shifter (allowing shift + operations with a single instruction)
Could probably be done much smaller on newer ARM CPU with
Thumb
mode.
Advantage of this method is easy real-time radius adjustments
of the circles which can lead to other effects (without much costs)
such as morphing them into a ball.
I am not sure how this one would compare on x86 architecture,
could reach 128 bytes on DOS platform perhaps (less ?) if the FPU /
SQRT is used although it would be slower since ones would iterate
over all the screen (unless buffering is added), minsky circles can
also be done very efficiently (~8 bytes!) on x86 by using MOVSX
instruction.
2024 Update : The thickness loop is entirely avoidable
by doing the circle thickness with the circle algorithm instead
(see
this; the idea is to slightly perturb the stability of the
algorithm to trace outside of the usual orbit), this save some
bytes and may be a bit faster overall because the thickness loop is
no more (= one branch less which is at least 4 cycles per
iteration), the thickness will then be iterations dependent.
Another optimization that i see now is using a two instructions
minsky instead of a three instructions one and using a downscale
step to ramp the precision if needed, this save 4 bytes.
the ARM code for the RPI version (i use BBC
BASIC assembler)
back to top
