Writing a small Forth-based RPI OS : Part 2 (ARM Forth dialect implementation)
This article focus on the ARM implementation of a Forth
dialect, see
part 1 for a full Forth introduction and U-Boot setup, part 3
is coming soon.
Contents
- Introduction
- Initial interpreter implementation: A lightweight ARM Forth core
- Simplifying through unifying; a compile only Forth
- More Forth words: a base dictionary for a general purpose dialect
- Syntax customization with a small parser (a mistake ?)
- Reduced stack juggling with variables / registers
- Data area and adding strings, arrays and quotations
- U-Boot I/O primitives
- Optimization: Constant load for 8-bits number
- Optimization: Inline expansion
- Full example program
- Conclusion
Introduction
In
part 1 i explained how to setup a Raspberry PI Zero
1.3 with Das
U-Boot to load a custom binary and use the U-Boot API from ARM
code for easy I/O.
In this article i details an ARM implementation of a low
level Forth interpreter called ARM-ForthLite.
I then details various improvements to revamp it into a
compiler called GnosTh with syntactic
changes (C like) as an experiment and to suit my needs. (see my
mastodon feed for the
progress history)
This Forth is actually a low level follow up of
a prototype made in JavaScript.
My initial idea was to use this dialect to serve as a shell
and as a general toolbox for a simple OS (development, running
software etc.) but i decided to simplify it further (will show in
part 3 !) by going back to Forth roots (self contained; IDE
/ OS like) by rewriting the dialect in itself as a tokenized
version with a simple environment built around. A decision which
was heavily inspired by colorForth.
Initial interpreter implementation: A lightweight ARM Forth
core
The initial version of my bare metal ARM Forth interpreter can
be found here, it is a
minimalist ~440 bytes Forth skeleton which use Subroutine Threaded Code, it was used as a base to
tinker with Forth and bootstrap a Forth compiler for a Raspberry PI
0.
Here is some notes about the implementation :
- it use Subroutine Threaded Code which seemed
the most attractive choice to expand it later into a
compiler
- parse hexadecimal numbers on unknown words which is a bit dodgy
for many reasons but i like it, it is simple to change (or mix)
radix
anyway
- stack top is stored into a register r4, implementation use all available registers for additional speed
- target is a RPI Zero 1.3 (ARM1176JZF-S), it target ARMv6 architecture but probably works on any ARM that support conditional instructions, side goal is ARMv2 (Acorn Archimedes) support
- no REPL nor much primitives bundled by default, idea is to stay
flexible so it serve as a base and a REPL can be bootstrapped
around with a chosen set of primitives
Implementation is quite small even if the focus wasn't code
size, i chose some shortcuts that made the code simpler such as
:
- doesn't trim extra white-spaces; should always be exactly one white-space between words (unless an option is enabled)
- no negative numbers parsing (can be built easily)
- no errors handling such as stack underflow although i
implemented a rudimentary one in earlier commits (note : same in my
dialect, it is quite raw !)
- no unknown words, they are parsed as number (base 16)
Source
code is fully commented.
The implementation is not cache friendly, the cache isn't
invalidated on code generation so ARM independent instruction /
data cache should be disabled on some CPU for full
reliability.
Interpreter context
The interpreter context is made of data structures (data
stack, return stack, dictionary) with their associated pointers
stored in dedicated registers along with top data stack value (for
speed) and interpreter mode as a binary flag.
These registers are dedicated to the interpreter so they
should never change between interpret calls (except r1) to keep the
context.
Keeping almost all the interpreter state in registers makes
interpreter context switching easy, it is just a matter of saving /
restoring these registers after delimiting RAM area for each
interpreters, implementation code is also straightforward and easy
to read.
@ ============= FORTH INTERPRETER
@
data stack addr.: sp
@ return
stack addr.: r0
@ input
buffer addr.: r1
@ dict last word addr.:
r2
@
compile mode: r3
@
stack top value: r4
@
dict. end addr. :r14
@ ===============================The difference between
the high level implementation and this one is the introduction
of the return stack which was abstracted away in the high level
interpreter, it is necessary here as a way to return from sub
routines (word call) and avoid cluttering the data stack.
Dictionary pointers could be squeezed to a single pointer
since dictionary end address can be computed from the last
dictionary word but keeping these two pointers into registers makes
the implementation simpler.
Entry point (parsing
words)
The entry point of the Forth interpreter is essentially a
Forth word parser, a Forth word is printable
characters delimited by a white-space (or NUL)
character, this code iterate on the input buffer and continue to
iterate until it hit a ASCII non printable characters, it then
compute the word length from the word boundaries addresses then
branch to the find_word label or jump back to the
interpreter caller when length is 0.
I made some shortcuts to make it as simple as it can be so it
doesn't skip extra spaces and non printable characters are all
considered the same way so it is just a matter of printable (words)
versus non printable characters.
forth:
@ =================== READ A WORD ; any printable characters
delimited by ' '
@ ===================== ON RETURN ; does not skip / trim extra
spaces !
@
end addr: r1
@
word length: r5
@
word start addr: r9
@
cond. flags updated
@ ===================== CLOBBERED
@
r5, r8, r9
@ ===============================
read_word:
mov r9, r1
0:
ldrb r8, [r1], #1
subs r8, #' '
bgt 0b
subs r5, r1,
r9 @ get word
length; update condition flags
subgts r5,
#1 @
adjust if not empty
bne
find_word
@ find word if len > 0
retNote that i don't use any
branch and link relative instructions since i make use of all
registers including r14 (link register)
which is used as a dictionary end pointer.
First address on return stack is the return address of the
Forth interpreter.
Word dictionary lookup
The word dictionary is a linked list with the following data
:
- pointer to previous element or 0 when no previous
elements
- word flag along with word length (as a byte in my case so maximum word length is 255 characters)
- word identifier as NUL terminated string
- a data section which hold the word code in my case (always end
with a RET macro call which is an instruction which pop the return
stack directly into PC)
This code search the parsed word within the dictionary by
first comparing their lengths then comparing individual characters,
it jump to eval_word when the word is found or fall through
parse_number if not.
@ =================== FIND A WORD
@ last dict. word addr:
r2
@
word length: r5
@
word start addr: r9
@ ===================== ON RETURN
@ found word dict
addr:r12
@ found word name end addr:r10
@ ===================== CLOBBERED
@ r6, r7, r8, r10, r11, r12
@ ===============================
find_word:
mov r12, r2
0:
ldrb r7, [r12,
#5] @ get dict. word len.
cmp r5,
r7
@ word length match ?
bne
2f
@ skip word if not
add r10, r12,
#6 @ get dict word
addr.
mov r11,
r9
@ get word addr.
1:
ldrb r6, [r11], #1 @ word char.
ldrb r8, [r10], #1 @ dict. word char.
cmp r6, r8
bne
2f
@ skip word on != char.
subs r7, #1
bne 1b
b eval_word @
found
2:
ldr r12,
[r12] @ get
previous dict. word addr.
cmp r12, #0
bne
0b
@ continue until no words to search forChecking length is a speed optimization. (optional)
Number parsing
Unknown words are always parsed as hexadecimal number in my
interpreter to simplify the implementation, the number is either
pushed immediately to the data stack or compiled into the current
definition on compile mode.
Early versions didn't require numbers to be prefixed but i
added a prefix requirement later to be compatible with Gforth and avoid
collisions with other words which may happen with hex. values,
prefix is unchecked though so it can be any symbols.
@ ================== PARSE NUMBER
@
compile mode: r3
@
word length: r5
@
word start addr: r9
@
0: r10
@ ===================== ON RETURN
@ ===================== CLOBBERED
@
r4, r5, r7, r10, r12
@ ===============================
parse_number:
0:
ldrb r7, [r9, #1]!
@ get char. + skip prefix
subs r10, r7,
#87 @ get char. numeric value
(a-f)
sublts r10, r7,
#'0' @ get char. numeric value (0-9)
addge r12,r10,r12,LSL
#4@ n * 16 + v
subs r5, #1
bgt 0b
cmp r3, #FORTH_IMM_MODE
@ immediate mode ?
pusheq { r4
} @
immediate mode: push old value to Forth stack
moveq r4,
r12 @
immediate mode: push new value to Forth stack
beq read_word
1:
@ else: compile mode
adr r10, 2f
b compile
2:
@ generated code (compile mode)
.word
0xe52d4004 @ opcode: push
{ r4 }
.word
0xe59f4000 @ opcode: ldr
r4, [pc, #0]
.word
0xe28ff000 @ opcode: add
pc, #0 @ value is stored after this instruction, it is stored by
"compile" from r12Word definition (compilation) and evaluation
A word is evaluated immediately or compiled once found.
This code check the interpreter mode and the word flag to
decide whether the word is evaluated or compiled, it put
read_word as return address and call the word code on
evaluation, it generate a return stack push instruction and a call
instruction on compilation.
@ =============== EVALUATE A WORD
@
compile mode: r3
@ found word name end addr:r10 ; unaligned ok,
will be aligned later
@ found word dict
addr:r12
@ ===================== ON RETURN
@ ===================== CLOBBERED
@ r0, r5, r6, r8,
r9, r10
@ ===============================
eval_word:
add r10,
#4
@ adjust word name end addr for alignment
cmp r3, #FORTH_IMM_MODE
@ immediate mode ?
ldrb r8, [r12,
#4] @ get
word flag
andnes r9, r8,
#0xff @ in compile mode :
is an immediate word ?
bne compile_word
adr r5, read_word
stmdb r0!, { r5
} @ push return address
bic pc, r10,
#3 @ align (point
to code addr.) and jump to word code
compile_word:
bic r12, r10,
#3 @ align (point to code
addr.)
adr r10, 1f
b compile
1:
@ generated code (compile mode)
.word
0xe28f5008
@ opcode: add r5, pc, #8
.word
0xe9200020
@ opcode: stmdb r0!, {r5}
.word
0xe51ff004
@ opcode: ldr pc, [pc, #-4] @ word code addr. to jump to, stored
after this, stored by "compile" from r12
@ ======================= COMPILE
@ generated code
addr.:r10
@
value to store:r12
@ current def. code addr. :r14
@ ===================== ON RETURN
@ ===================== CLOBBERED
@
r9, r10, r11, r14
@ ===============================
compile:
ldmia r10,
{r9-r11} @ load
generated code
stmia r14!,
{r9-r12} @ store
generated code at current definition code addr.Note that there is alignment
instructions (due to the variable length word name) so that the
word code pointer fall within a 4 byte boundary which is a
requirement on early ARM.
Primitives
A minimal set of primitive words is bundled in :
immediatewhich set the previously defined word flag to immediate:which is the character used to specify a new word definition;which is the character that ends a word definitioncreatewhich create a new word with the default behavior of pushing content address on stack+which is an operator word that adds the two value on the stack and push back the result- conditionals and loops (see improvements section)
- many other operators that map nearly 1:1 to underlying ARMv2 instructions (arithmetic, logical etc.)
These primitives are static data, they constitute the base
dictionary that will be used by the interpreter, i use a
forth_word
macro as a convenient way to define them so i just needs to
provide the word name, flag and the word code body, this data is
inserted statically into the dictionary, the word length is
automatically computed by the macro.
I also use macros as a less obscure way to manipulate the
return stack. (RET instruction)
The new word definition is the densest primitive as it must
create a new dictionary entry, it have its own word parser that
takes the word that follow
: and copy it into
the dictionary along with the word length, flag and link to the
previous dictionary entry, it also switch the interpreter global
state to compile mode so that subsequent words will be compiled
instead of evaluated. (unless a word flag is set to
immediate)Here is a very minimal dictionary :
.include "dict_utils.inc"
forth_word "immediate"
mov r5, #FORTH_WORD_FLAG_IMMEDIATE
strb r5, [r2, #4]
ret_opcode:
ret
forth_word ":" FORTH_WORD_FLAG_IMMEDIATE
str r2,
[r14]
@ store previous word addr.
mov r2,
r14
@ update last dict. word addr.
add r14,
#6
@ point to name field
0:
ldrb r8, [r1], #1
cmp r8, #' '
strgtb r8, [r14],
#1 @ copy name
addgt r7,
#1
@ update length (note: r7 implied to be 0 before loop which is the
case after "find_word")
bgt 0b
strb r3,
[r14]
@ append \0 (note: use r3 since mode is 0 at this point; nested
defs don't make sens)
strb r7, [r2,
#5] @
store word length
mov r3, #FORTH_COM_MODE
@ switch to compile mode
strb r3, [r2,
#4] @
store FORTH_WORD_FLAG_DEFAULT flag (note: use r3 since COM_MODE is
same constant)
add r14, #4
bic r14,
#3
@ align to get to end of dict. addr.
ret
forth_word ";" FORTH_WORD_FLAG_IMMEDIATE
mov r3, #FORTH_IMM_MODE
@ switch to immediate mode
adr r7, ret_opcode
ldr r7,
[r7]
@ get opcode for RET instruction
str r7, [r14],
#4 @
store RET opcode at the end of the newly defined word
ret
forth_last_word_addr:
forth_word "+"
pop { r5 }
add r4, r5
ret
forth_dict_end_addr:
The power of Forth is that all the primitives can be redefined
easily by modifying the dictionary as above or by redefining them
at runtime to create a different dialect, for example adding a line
comment to the dialect just require to choose the characters (for
example
// ) and write the code that will
skip the characters from this point on until the next line, this
word should likely have an immediate flag as its shouldn't
be compiled. The only inconvenience of defining a line comment that
way is that // should be delimited by
space as it is still parsed as a Forth word.In other Forth the word parsing code may share the same
routine as the main parser code to alleviate redundancy, it may be
bundled as a primitive as well, i ignored most reflection features
in my Forth but they are highly powerful feature to have. (see
frugal Forth for
example, especially init.fs) Many chunk of code are shared
and implemented as a primitive in most advanced Forth
implementation.
Bare metal usage sample
The sample code is a bare metal usage example of the Forth
interpreter, it initialize an interpreter context (memory layout,
state) and evaluate a line of Forth code.
Here is the line that it interpret :
: 1e $f $f
+ ; $1eWhat it does is define a word called
1e
containing the operations of a simple addition between two numbers
15+15 then call this newly defined
word.The result is placed at the top of the data stack r4
and is (in base 10, after the execution) : 30
@ FORTH MEMORY LAYOUT CONSTANTS
.equ FORTH_DATA_STACK_SIZE, 1024 * 1000 @ always multiple of 4
.equ FORTH_RETN_STACK_SIZE, 1024 * 1000 @ always multiple of 4
.equ FORTH_DICT_SIZE, 1024 *
1000 @ always multiple of 4
.global _start
_start:
@ = FORTH SETUP
@ data stack
adr r8, forth_data_stack_addr
ldr sp, [r8]
@ return stack
adr r8, forth_retn_stack_addr
ldr r0, [r8]
@ input code
adr r1, forth_code
@ dict last word
adr r2, forth_last_word_addr
@ compile flag
mov r3, #FORTH_IMM_MODE
@ dict end
adr lr, forth_dict_end_addr
@ save return addr. on return stack
stmdb r0!, { pc }
b forth
@ r4 has value 1e at this point
0:
b 0b
.include "forth.s"
forth_data_stack_addr:
.word (_end +
FORTH_DICT_SIZE + FORTH_DATA_STACK_SIZE)
forth_retn_stack_addr:
.word (_end +
FORTH_DICT_SIZE + FORTH_DATA_STACK_SIZE +
FORTH_RETN_STACK_SIZE)
@ code to evaluate :
forth_code:
.asciz ": 1e $f $f + ;
1e"
.align 2
@ = FORTH DICTIONARY
.include "dict.inc"
_end:
Debugging
A simple way to debug Forth behaviors is to check stacks depth
and Forth context registers, this may quickly indicate as first
diagnostic a stack overflow / underflow which may quickly hint at
implementation (or Forth code) issues.
22/12/2025 and later improvements
I got back to this Forth in late 2025 / early 2026 after i wrote a Gforth ARMv2 assembler, this was a perfect opportunity to make this light Forth run the assembler code (and thus be compatible to a small subset of what Gforth support), many conventional words were added to the dictionary (see sources) :- create was added and reuse parts of the code, this word act like : (create a word) except that it is not immediate and doesn't change mode, it also attach the default behavior of putting its content address on stack when called, this is an useful word to store any data in the dictionary, it is a key word to define global variables for example or any kind of data such as arrays (in combination with allot)
- conditionals and loops are implemented as ARM primitives, a lightweight option in my situation so i don't have to implement branch and primitives that expose the return stack just to make loops / conditionals in Forth, main disadvantage is that portability take a hit... a Forth implementation work in a platform independent way and implementation can be as easy as copying the well known snippets (see sectorforth 01-helloworld.f sample)
- added a runnable ARMv2 RISC OS version able to load / evaluate a Forth source from disk
- experimented with relocatable dictionary (on dictreloc branch) with slightly more optimized generated code, code didn't grow much
Simplifying through unifying; a compile only Forth
As i wrote the Forth interpreter i realized that it was not
too far from a compiler already, i just needed to drop the two
modes and makes a compile only Forth ! The slight difference is the
need to jump at the compiled code after running through the
input.
To simplify further i dropped the ';' word later on.
The realization came from trying to simplify the dialect and
optimizing for speed, the Forth interpreter wasn't necessary for my
use case.
Peoples also realized this 30
years from now !
The program code was the last word of the dictionary in the
first implementation, it works but adds several constrains so i
made it a bit more flexible by separating the program code from the
dictionary, i also added a primitive to mark any definitions as the
entry point (entrypoint word), it was more flexible that way
and swapping entry point can be handy for debugging or prototyping.
The entry point word switch the compiler code output address from
dictionary to program output address so the definition code is put
into program area instead of the dictionary.
I also dropped immediate definitions by design to improve
dialect overall cohesion, this makes the Forth much less reflective
by default so much less powerful, it still support "reflection"
through immediate primitives and literals.
It may be possible to gain some reflection back by making some
words (such as stack ones) works in mixed mode (with immediate and
default constructs) without having to redefine an immediate version
by having the same stack implementation on compile / runtime which
isn't the actual case. (the compiler stack does not have its top
value stored in a register)
More Forth words: a base dictionary for a general purpose
dialect
The basic Forth above isn't a full language yet, it is the
base skeleton by which a Forth dialect can be defined and further
refined, the dictionary lacks many primitives / words to be useful
in a general way, the power of Forth is that this set of words can
be very simple / bootstrapped (see sectorforth or
milliForth;
a great way to be portable although performances take a hit) or
dense (Gforth), either general
purpose or task focused ones, they just have to be written !
Words
My general purpose Forth dialect at the time of writing this
article include these words :
- stack manipulation (dup, drop, swap, over, rot)
- memory access (@ !) also have the equivalent for byte access (db@ db!)
- data allocation (allot), a way to get data length (dlen) and a
way to align data (align)
- logic (0= 0<> <> = < > <= => ~ & | ^
<< >> >>>)
- flow controls (loop, again, until, for, do, next, if, else,
then, call, case)
- arithmetic (* / % */ - + negate >>+ >>-)
- registers access (A! A@ B! B@ C! C@ D! D@)
- I/O mostly provided by Das U-Boot API (getc, putc, tstc, pix etc.)
- also have some special immediate words (entrypoint, #!)
- Das U-Boot specifics (use extended U-Boot API) :
cache_care
My Forth dialect has ~70 primitives, it is inspired
by Chuck
Moore 2000s Forth and also heavily inspired by C as i am
accommodated to some of the concise symbols that C use, Joy,
Factor, r3 and DSSP were also
inspirational although i didn't borrow much from them.
It should be seen as a prototype / transitional step
towards a colorForth
environment.
I don't expose the return stack and it only handle
integer arithmetic, fractional numbers can be represented as
fixed-point.
I will not details the implementation of most of the
primitives, many are trivial and nearly map one to one to the
underlying instructions set, non trivial constructs such as loops
and conditionals will be explained though.
The language support include
directive in the comments, they are preprocessed at build time
by tools such as AWK and the build process
convert an ASCII source to a set of .ascii gas assembly
directives.
Note that the primitives are tailored for a Forth in
compile only mode (might works slightly differently in the Forth
presented above), i also use r5 as stack top instead of r4 to
reflect the latest version of my dialect, the return instruction at
the end of each primitives is omitted since my dialect insert it
automatically.
Numbers are not prefixed compared to my light
Forth.
Loops
Here is the code for the loop, again
and until construct (again is an infinite loop,
until is a conditional loop, note that i use loop
instead of begin which is unconventional) :
forth_word "loop"
mov r6, pc
stmdb r0!, { r6 }
forth_word "again"
ldr pc, [r0]
forth_word "until"
cmp r5, #0
pop { r5 }
ldreq pc, [r0]
ldmia r0!, { r6 }
Not too difficult to implement, it use the return stack to
store the address to jump back to, the return stack is convenient
but may become less readable with complex constructs because the
stack is shared with subroutine calls, some Forth adds a loop
control stack to simplify this at the cost of introducing yet
another stack.
I have two other loop construct, for and
do, they are handled with the same end word which is
next, for iterate backward from n (user
provided value) to 0 (included), do mimic a C for loop and
is able to iterate from n to another given value at a given
step size, the direction of the iteration is automatically detected
:
forth_word "for"
mov r6,
r5 @ start value
mov r5,
#1 @ step
mov r7,
#0 @ end value
rpush r5-r7
@ push loop parameters on return stack
rpush
pc @ push
start address of the loop body
mov r5,
r7 @ "push" iteration
value on data stack (stack top is r5)
forth_word "do" @ same as for
but takes 3 parameters instead of 1
pop { r6-r7 }
rpush r5-r7
rpush pc
mov r5, r7
forth_word "next"
rpop r6-r9
cmp r8,
r9 @ determine iteration
direction
addgt r9, r9, r7 @ positive iteration
cmpgt r8, r9 @
check stop condition
sublt r9, r9, r7 @ negative iteration
cmplt r9, r8 @
check stop condition
addle pc, pc, #12 @ jump out of the loop when
stop condition is reached
rpush r6-r9
@ otherwise push parameters back
push { r5 }
mov r5,
r9 @ "push" iteration
value on data stack
mov pc,
r6 @ jump to start
address of the loop body
The return stack is used as a temporary storage for the loop
index.
Unlike conventional Forth my dialect doesn't expose the
iteration value (loop index) through other primitives such as "i"
and "j", the iteration value is instead directly pushed on the data
stack after for or do and it is up to the
user to either drop it or use it later.
A way to break out of a loop at any given moment may be handy
but is not as simple to implement because the code between "leave"
and "next" must be skipped and making it work for all loops end
word adds difficulty, i used to have a constrained "goto" but this
was an ugly hack so my dialect doesn't support this right now, a
way to implement a "leave" word would be to :
- introduce another stack or use a stack that is untouched by any
other immediate words
- allow words to have a mix of immediate code and compile code
(this step might add a bit more complexity to the
compiler)
- all loop words definition should have a mix of immediate and
compile code; compile code will stay as is with added code to skip
entire loop body (including loop end block code; it must also clean
the stacks), the added code is just a forward jump of yet
unresolved length, immediate code push the location of the forward
jump length on the newly introduced stack so the length can be
resolved later on
- loop end words must also have a mix of immediate and compile
code; compile code stay as is, immediate code pop the newly
introduced stack to get the skip length location, it then compute
the skip length which is stored at the location
- "leave" primitive code use the return stack to retrieve the loop start location and jump at the newly added skip loop body logic
Note : leave can be replaced by
the simpler combination of unloop and
exit which clean loop params from return stack and
return from the word, has gotchas (loop must be the last construct
of the word) but is sufficient in many cases
Conditionals
Conditionals implementation also have some complexity because
the interpreter doesn't know where to jump to when a conditional is
hit, this information is only available when a then word is
encountered later on. (i.e. there is references to resolve later
on)
My implementation generate the conditional code with
room for a jump on the if word, i compute a jump length
instead of resolving a jump address, this jump length is
computed later on by else or then, i use the return
stack once again to hold information about the location of the jump
length that must be patched :
forth_word "if" WORD_IMMEDIATE
adr r5, forth_if_code
ldmia r5,
{r5-r10} @
load generated code
stmia r14!,
{r5-r10} @ copy generated
code
rpop r5
rpush
r14
@ push body length addr.
mov pc, r5
forth_if_code:
cmp r5, #0
pop { r5 }
addne pc,
#8
@ jump to if body
forth_skip_over_code:
ldr r6,
[pc]
@ get body length
add pc, pc,
r6 @ jump to
either "else" body or "then"
.word
0
@ if body length
forth_word "else" WORD_IMMEDIATE
adr r5, forth_skip_over_code
ldmia r5,
{r5-r7}
@ load generated code
stmia r14!,
{r5-r7} @ copy
generated code
rpop r5-r6
sub r8, r14,
r6
@ compute body length
str r8, [r6,
#-4] @
update if body length
rpush
r14
@ push body length addr.
mov pc, r5
forth_word "then" WORD_IMMEDIATE
rpop r5-r6
sub r8, r14,
r6
@ compute body length
str r8, [r6,
#-4] @
update "if" or "else" body length
mov pc, r5
Switch statement
My dialect leverage the implementation of quotations
(lambdas / anonymous functions) for switch
statements, it only have a case word which takes two
values to compare to plus a quotation evaluated on a successful
compare, the word drop the last two values on stack on a failure so
other cases can be evaluated , the last code of the quotation is
the default case, the word is implemented like this :
forth_word "case"
pop { r6-r7 }
cmp r6, r7
moveq r9,
r5
@ get case blocks addr. (when cond. is true)
popeq { r5
}
@ restore stack
moveq pc,
r9
@ call case blocks
mov r5,
r7
@ continue with the value to compare to otherwise
And used like this :
getc {
'a' {
"getc result: 'a'"
puts
} case
'b' {
"getc result: 'b'"
puts
} case
"unhandled getc value: " puts putc ; default
case
} call
Quotation evaluation is done through the call word
which is a jump to the address pushed on return stack by "{...}"
construct plus a return stack push to get out of the
quotation :
forth_word "call"
pop { r6 } @ see below
mov r7, r5
mov r5, r6 @ update TOS after pop
(only due to the usage of a register for stack top value)
rpush pc @ go back to
after call once the quotation is evaluated
mov pc, r7 @ jump to quotation code
start address
Syntax customization with a small parser (a mistake ?)
A lot can be done with Forth minimal syntax (words delimited
by spaces) but i still wanted some small amount of conventional
syntactic sugar to define variables or have conventional strings
definition. ("..." instead of s"
...")
So i started to deviate from Forth minimal parser (as seen
above) by going for a small parser.
Was it worth ?
Not sure, it add flexibility perhaps while remaining fairly
lightweight; it contribute to a smaller binary rather than having
specific words in the dictionary but it is only worth for a tiny
amount of constructs in my case... (variables, immediate number and
verbatim value) so it could have been avoided entirely by making
some small edge cases on the initial parse loop... it is also more
errors prone to get right, i also understood later that all the
edge cases the parser solve vanish when the ASCII input is replaced
by a tokenized input. (the colorForth approach)
Syntactic features
of my Forth dialect
- strings : "..."
- arrays definition : [0 1 2 3 ...]
- character
literal : 'a'
- quotations : {...}
- variables definition : >my_variable
- immediate number (push a number on compiler stack) :
#42
- verbatim value (compile verbatim value) :
$42
- line comment : ;
Reduced
stack juggling with variables / registers
Stack juggling (also called "stack noise") is related to all
the stack manipulation that must be done to manipulate stack data
values, it is not transparent in Forth unlike C due to its stack
machine model; data values must sometimes be reordered by the user
which lead to high usage of stack manipulation words which might
lead to highly verbose code and slightly less readable code.
There is some rules that one may apply to reduce stack noise
(factor into small definitions, keep up to 3 values at most on
stack) but it is not entirely avoidable as is.
One of the first feature added to my dialect to reduce stack
juggling and improve readability was registers access and named
parameter, i quickly found out that it was not sufficient to
reduce stack juggling as much as i wanted (especially in loops) so
i quickly fused it into a "variables" concept instead. I still kept
registers access as it is a good way to speed up a
program.
The usage of variables is slow but effectively eliminate stack
juggling, i like the versatility of having variables (slow), stack
words (fast), registers access (very fast) with readability
variations, all of this blend easily with the base features of the
language and doesn't add much complexity.
A variable in my dialect is defined with a ">" character
immediately followed by a word which basically means that whatever
is on stack is stored into that word, the value can be retrieved on
the stack through the word. Variables name must starts with an
ASCII character higher than 64. (this prevent words such as '>='
and '>>' etc. to be interpreted as a variable
definition)
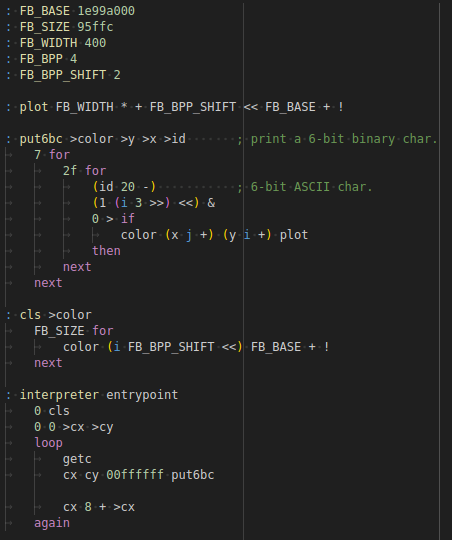
early implementation of variables to avoid
stack juggling
Data
area and adding strings, arrays and quotations
Variables were initially stored in the base dictionary but i
realized that many form of anonymous data might be stored there
later on (strings, arrays etc.) thus i introduced a separate area
to store all data (similar to the data segment) so
it doesn't mess with the base dictionary. Also tried to place data
where they were defined but this had performances impact due to
generated jump instruction to skip over the data, some features
were also harder to add due to this later on.
Variables
Variables are defined like a word definition but are stored in
the data area, they are parts of the dictionary (linked with it) so
the compiler find their symbol through a regular dictionary search,
the compiler distinguish between regular word and variables through
a word type flag.
A local variables implementation could be introduced easily by
limiting the word search on a variable definition to the current
definition, local variables actually help a lot for things like
recursion. Perhaps a better implementation is to store them on the
return stack !
String type
My dialect support a multi-line conventional "..." string
syntax, it support null-terminated
string and
length-prefixed string at the same time. The implementation
generate code that push the string address on stack.
The string length can be retrieved through the dlen
primitive.
Array
The dialect also support the definition of integer arrays with
"[0 1 2 3]" syntax, the implementation is similar to the string
implementation (it is length-prefixed) although the parser state
switch to "array" mode; parse_number routine is then reused to
directly put parsed values as a linear series of numbers in the
data section, the parser state is reset on "]".
Quotations
Quotations
is supported in my dialect with "{ ... usual code... }" syntax. It
enable the definition of anonymous block of code. (lambdas /
anonymous functions)
Quotations does not use the data area, code is generated
inline.
The implementation is straightforward :
- upon "{" the compiler generate code that push the quotation start address on stack and also generate a jump to skip over the quotation body (jump length is not yet resolved)
- upon "}" the compiler generate a RET instruction (which use the
Forth return stack) and resolve the previous jump length (it
compute the code body length from the start / end address)
The call primitive can be used to "call" a quotation.
(see code above)
Quotations are powerful as they can simplify all "blocks" /
control structures such as conditionals or switch statement, an
example in this dialect is the implementation of the "switch"
statement which has a quotations implementation.
The array statement can be replaced by using a quotation with
verbatim literals :
{
$42 $deadc0de ; verbatim literals
} ; data start address is now on stack
; quotation could also be called to put all the data on stack when
the data is defined as regular values (not
verbatim)
See also how the DSSP programming
language use blocks to simplify some constructs, it has some
similarity to quotations although they are not anonymous.
Data allocation word:
allot
The array construct is handy but a way to programmatically
allocate arrays is missing so the allot primitive was
implemented :
forth_word "allot" WORD_IMMEDIATE
pop { r5 }
add r10, r4,
#4
@ assign data addr. (+4 to skip length)
adr r7, number_code_generic @ reuse generic
number load code
ldmia r7,
{r7-r9}
@ load generated code
stmia r14!,
{r7-r10} @ copy generated
code
str r5, [r4],
#4
@ store length
add r4, r4,
r5
@ offset data
add r4, #4
bic r4,
#3
@ align
This word is immediate, it is called when the code is
compiled thus i also needed a way to define immediate numbers (due
to a
design issue) which is done by prefixing a number with
#.
The first use of allot was to define a static buffer
for a number to string conversion routine :
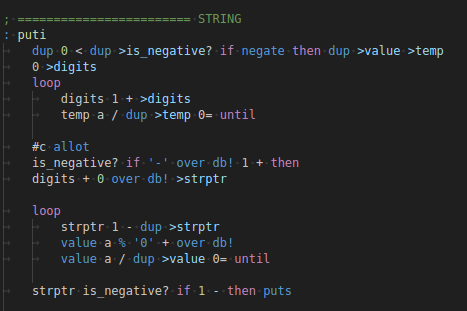
number to string conversion in my
Forth dialect
I also added an "align" word later since
a way to align the next alloted data was missing, alignment is a
requirement in some bare metal cases. (mailbox CPU / GPU interface
requirement)
U-Boot I/O primitives
I/O was implemented with U-Boot standalone API at first (see
first article) then U-Boot API (which has storage device access),
it was quite time consuming as it required to tinker with U-Boot a
lot and constantly gathering knowledge on how to interface with it
at this level.
The result is a set of assembly macros that save / restore
U-Boot context (stack and global_data address) plus some macros for
standalone API calls and a lengthy macro for the main API
interface.
See this
file for the U-Boot macros.
Optimization: Constant load for 8-bits number
An easy optimization to do was to detect 8-bits number and
generate a constant load instruction which is way faster than a
data load; code that directly load the number into the stack top
register.
Optimization: Inline
expansion
My dialect inline code by
default for performance reasons, it was fairly easy to tweak the
compiler to generate inline code from the use of Subroutine Threaded Code by directly copying the
word body code instead of generating a call instruction.
An early implementation issue was to determine the word body
length which was solved by going for a doubly linked
list dictionary implementation. (but not a XOR
implementation)
Also had issues with the code generation of some primitives
(conditionals etc.) as i used to patch by address initially, i
switched to patching by jump length instead which is actually way
more flexible.
Inline expansion brought some other issues such as broken
recursion which was addressed by detecting self calling words, it
default to a STC model in this case. I later found out that this
sort of recursion in a traditional Forth use a "recurse" word
which has a simpler implementation than allowing self calling
words. (less edge cases)
There is no mutual
recursion support in my dialect due to lacks of forward
declaration, recursion is also a bit dodgy with global
variables.
Inline expansion can bring easier optimization later on such
as reducing a set of words to a smaller set of words.
Early benchmark
I did a crude (visuals only; no measurements done) benchmark
with / without inline expansion which demonstrate that inline
expansion made the code between two to three times faster.
The benchmark is a graphics program that shows some procedural
logo gfx, the program run on a bare metal RPI Zero 1.3.


crude benchmark; left is STC model, right is
inline expansion optimization (ARM cache off)
Early dialect benchmarks against C / GCC optimization levels
I then did a C version of the same program and did some
measurements of the program compiled with my Forth dialect against
C / GCC optimization levels :
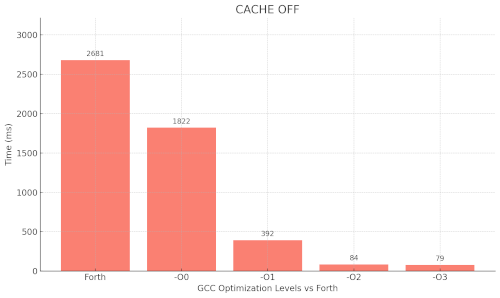
my Forth dialect vs GCC optimization levels
(ARM cache off)
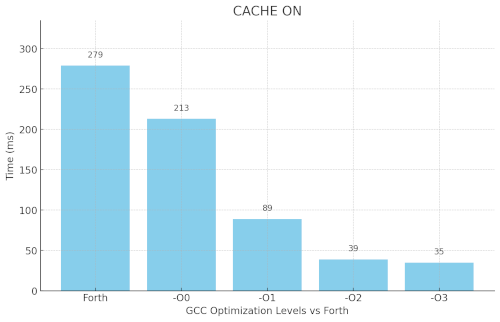
my Forth dialect vs GCC optimization levels
(ARM cache on)
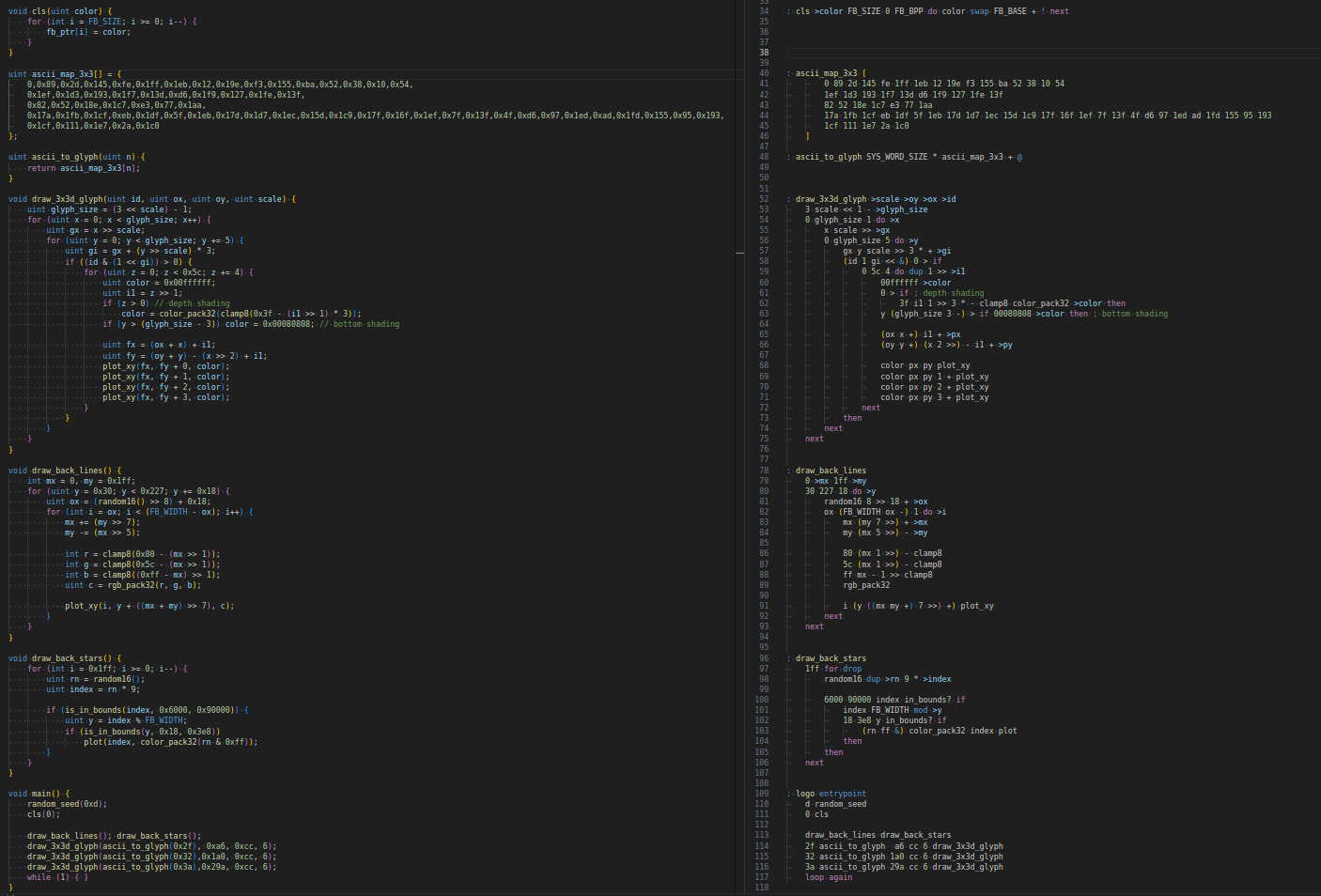
C code vs Forth dialect code side by side
(high
res)
Was not too bad as it approach GCC -O0
level.
Primitives were not optimized at this time, it
might be closer to -O0 level now with optimized primitives. (an
early round of primitives optimization brought the Forth down to
~262ms)
Reaching GCC -O0 level speed
Variables usage is slow in my dialect so most variables were
replaced by stack manipulation words (the Forth way !) + registers
and "pix" word was implemented to do optimized pixels access by
using multiply accumulate + base / offset store ARM instruction
:
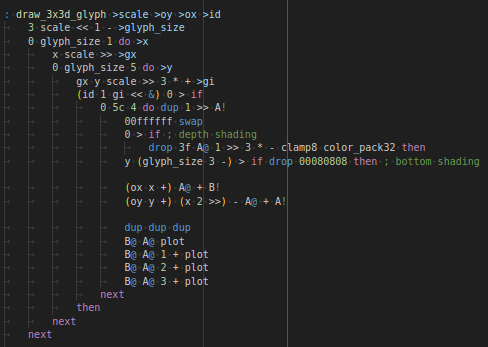
a quickly optimized variant (note : was still
using some variables !)
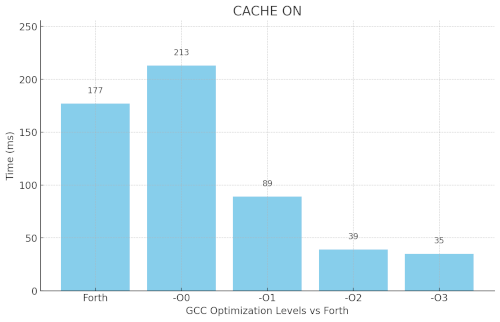
updated benchmark
Speed is now between GCC -O0 and -O1, not even
fully optimized ! (note : for some unknown reasons the C code has a
20ms gain when it is compiled for ARMv4 instead of ARMv6)
More speed
Follow up article : Transpiling
a Forth dialect to LLVM IR
If speed is a real concern then the best "uncomplicated" way
to gain "optimal" speed with this architecture is to convert the
primitives to an efficient intermediate
representation such as LLVM IR (from which many
architectures can be targeted, see the article above), this is a
quick way to leverage modern developments in optimization and may
result in optimal code at little cost, the only changes are the
primitives which should reflect the IR as it would be the new
target, tiny bits of the compiler code may change as well to
generate IR code for literals
and other constructs.
Threading technique
Without the inline expansion aspect (STC advantage) a direct
threading model (directly generate words address instead of a call)
may be
the fastest / easiest followed by indirect technique,
token threaded (Bytecode basically) is
also very attractive on some CPUs (such as cache less early ARM) as
it can be on par with indirect code with much smaller code + very
portable, may allow easy optimizations (peephole
etc.) also and inline expansion can be easier than direct /
indirect as well.
Full example program
Here is a full sample program of my dialect that print RPI
Zero 1.3 I/O device info (SD device) to screen and read / write to
it through U-Boot API calls :
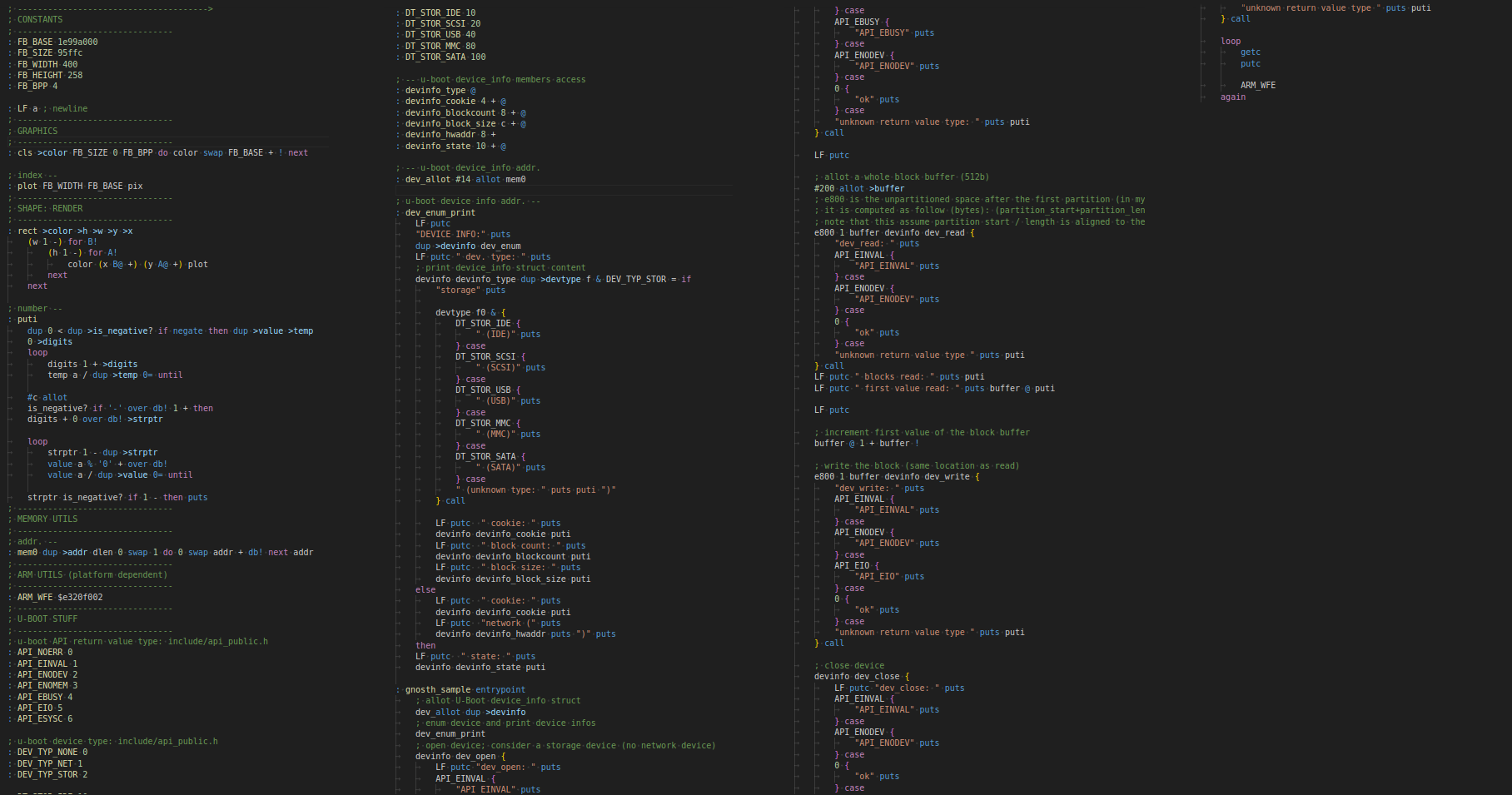
Conclusion
It was an incredible journey for me to go from a high level
Forth to a low level minimal prototype then build a complete
dialect / compiler out of it, most of the development, debug and
testing was done on bare machine (SD
swap !) with occasional help from cpulator, the compiler code is
about ~500 lines of assembly (total) which is still quite small for
all the features it pack, it can serve as a base to go
further.
There is some improvements here and there such as using the
same stack design for the compiler / runtime, doing tail-call
optimization or forward declaration or going back to a simpler
parser as i am not sure the actual parser is even needed.
This was my first take at writing a complete compiler /
language without much prior knowledge. (not even the
Dragon Book !)

the benchmark graphics program running on RPI
Zero 1.3
What is next ?
My next goal is to rewrite the dialect in itself but in a
tokenized way to make it even simpler, i also want to build a whole
prototyping environment around it. (colorForth
style)
back to top
